Introduction
The cloud is designed to be a host for applications that are realized as scalable services. For example a web server or the backend of a mobile app. In this case the application accepts random connections from remote clients and, based on the client’s request, it does some computation and returns a response. If the number of clients that are concurrently requesting service grows too large for one server to handle, the system should automatically spawn new instances of the server to share the load. Another scenario is an application that processes events from remote sensors to inform a control system on how to respond. For example, geo-sensors detecting ground motion tremors occurring in a significant pattern, then sound an earthquake warning. In this case the cloud part of the application may involve multiple components: sensor signal decoders, pattern analysis integrators, database searches, and alarm system interfaces. Another example is a large-scale data analytics system processing large amounts of text data. For example, a search index for the World Wide Web.
Each of these cloud applications illustrates one of three basic paradigms of programming the cloud. They are
Basic web server gateway. A single server that responds to requests from a user. Scaling is accomplished by replication. We will discuss this further in another section on Dockerized Science Gateways.
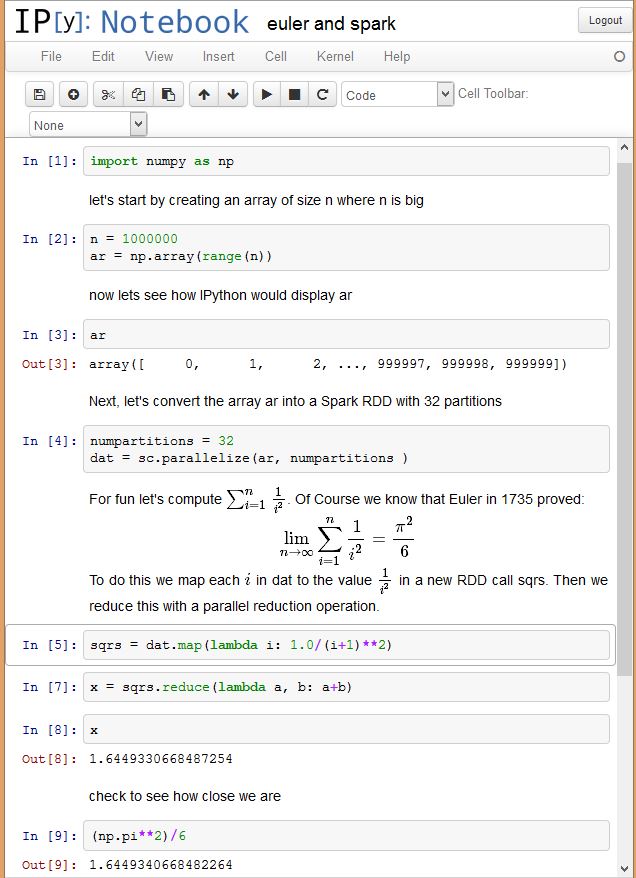
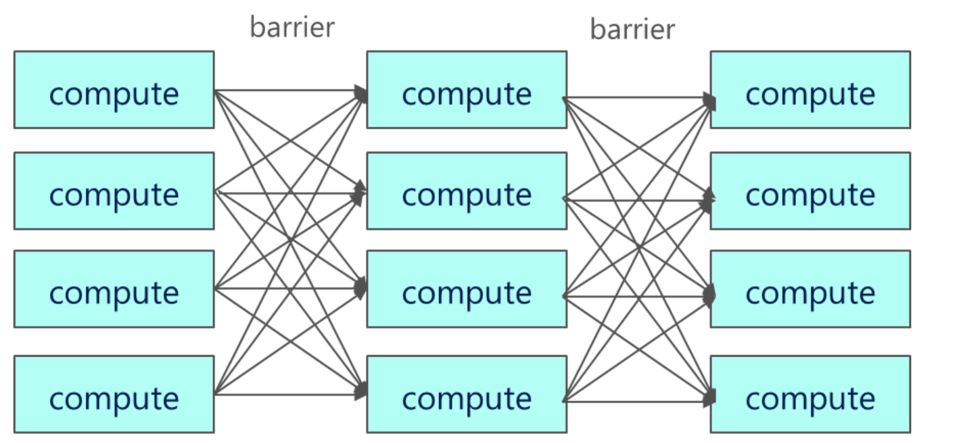
Bulk Synchronous Parallel methods. This is a very old and respected model for parallel programming characterized by running computation in a sequence of phases where each phase involves a single task that is executed in parallel on multiple servers. When the tasks terminate a barrier synchronization is used to permute the data so that the second phase of computation can begin. For example, Spark commands from the Scala REPL or Python API operate on distributed data collections in this manner. Hadoop Map Reduce is essentially a BSP program.
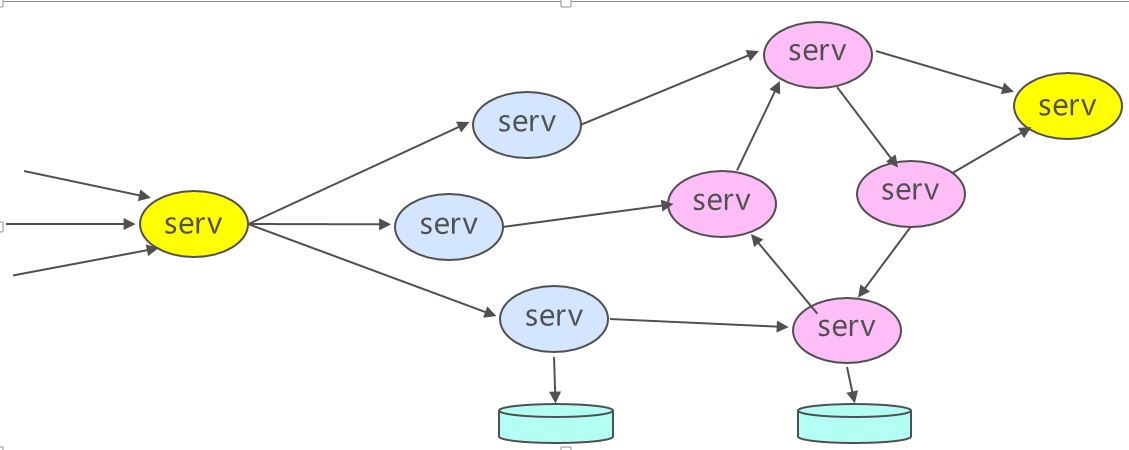
An asynchronous swarm of communicating processes distributed over a virtual network in the cloud. The individual processes may be stateless, such as a simple web service or stateful such as found in the actor programming model.
An excellent example of a tool for programming asynchronous swarms via actors is Orleans from Microsoft Research http://research.microsoft.com/en-us/projects/orleans/. Orleans has been used internally at Microsoft on some very large scale projects including the game Halo Online and it is now available as open source.
Microservices
Recently this asynchronous swarm style has been rebranded with a new philosophy under the name “Microservices’’. The problem addressed by microservices is that of how to design and build a large, heterogeneous app so that it will be secure, maintainable, fault tolerant and scalable? This is particularly important for very large, on-line services that need to support thousands of concurrent users. The app must remain up twenty-four hours a day but still maintained and upgraded. The software engineering approach to this problem is called “Dev Ops” and it integrates product delivery, quality testing, feature development, and maintenance releases in order to improve reliability and security and provide faster development and deployment cycles. From the programmer’s perspective this is a “you built it, so now you run it” philosophy. Updates to parts of this system occur while the system is running so there is a very tight integration of the developers with the IT-pros managing the system.
The microservice solution to this challenge is to partition the app into small, independent service components communicating with simple, lightweight mechanisms. The microservice paradigm design rules dictate that each microservice must be able to be managed, replicated/scaled, upgraded and deployed independent of the others microservices. Each microservice must have a single function and operates in a “bounded context”, i.e. having very limited responsibility and limited dependence on other service. When possible one should reuse existing trusted services such as databases, caches, directories, etc. All microservices should be designed for constant failure and recovery. The communication mechanisms used are varied and include REST web service calls, RPC mechanisms like SWIFT and the Advance Message Queueing Protocol AMQP system that are common in IoT applications and are well supported in the commercial clouds.
The microservice philosophy has been adopted in various form by many companies including Netflix, Google, Microsoft, Spotify, Amazon and others.
Docker, Swarm, Kubernetes and Mesosphere
To build a substantial microservice application one needs to build on a platform that can manage large collections of distributed, communicating services. Thanks to the open source movement we now have an excellent collection of tools for building and managing microservices. These are
- Containers. This revolutionary technology that allows us an alternative to deploying services as heavy-weight virtual machines. “Containers” run on a host OS and use basic services such as kernel namespaces and resource isolation provided by that OS. Docker containers contain all the OS components and libraries needed by the app, various user-added files and apps and instructions for what process to run. Docker exploits the host OS namespaces for isolation, control groups for resource management. It uses the Union File Systems so that containers are built as layers on existing FS. The company Docker.com also provides a registry of dockerized tools and application that can be downloaded. We show an example of using Docker and the registry in another section.
- CoreOS. As noted the host OS for Docker need not be very heavy because each container will have its own OS features and libraries required by the application. CoreOS is a basic “stripped down” version of Linux that contains only those tools needed to support Docker containers.
The tools for managing clusters of microservices hosting containerized microservices are many. The ones we have tested are
- Swarm. Docker.com provides a tool for managing clusters of servers running Docker container instances. We tested Swarm on Azure using the client Docker-machine and it was relatively easy to bring up a cluster of machines and deploy apps. Swarm shows great promise but it is still beta quality and we found the documentation still rather sparse.
- Kubernetes was recently released by Google and is based on the cluster management tools they use. We also found it relatively easy to deploy Kubernetes on Azure using another tool called Weave to support the networking. Kubernetes has an important feature not present in the other microservice cluster management tools. In Kubernetes every container lives inside a “pod”. Pods can contain a single Docker container instance or several instances. This is important because often a single microservice instance may always collaborate with another microservice instance of the same or different type. For example a Dockerized web server may need a private instance of a Redis cache or SQL database. These are relatively standard docker components, so there is no reason to deploy them in your web server container. Because each pod instance runs on a single server, the containers in the same pod share resources such as private directories. Communication within a server is going to be faster and more reliable than communication across the network.
- Mesosphere. One of the many products from the UC Berkeley AMP lab was a distributed computing operating system (dcos) called Mesos. It has since been spun off as a startup called Mesosphere.com. Mesosphere installed easily on Azure and it has proven to be extremely reliable. Because we use it so extensively we have an addition page about it here.
- Microsoft Azure Service Fabric. Microsoft recently released a development kit for a microservice orchestration framework that they have been using internally for a while. The SDK is easy to install into visual studio and it comes with an emulator so you can start building apps. I have not yet had a chance to try the full deployment. Mark Russinovich has a nice blog about this and an online video of a talk he gave describing the system.
In the next post, we will describe our experience building a microservice application to do document classification using machine learning tools. However if you want to get a feeling for how one can use Mesosphere and Python to build simple microservices, then we have a page where we show you all the gory details. It is called “Fun with Mesosphere and Microservices“.