
Research related to deep learning and its applications is now a substantial part of recent computer science. Much of this work involves building new, advanced models that outperform all others on well-regarded benchmarks. This is an extremely exciting period of basic research. However, for those data scientists and engineers involved in deploying deep learning models to solve real problems, there are concerns that go beyond benchmarking. These involve the reliability, maintainability, efficiency and explainability of the deployed services. MLOps refers to the full spectrum of best practices and procedures from designing the training data to final deployment lifecycle. MLOps is the AI version of DevOps: the modern software deployment model that combines software development (Dev) and IT operations (Ops). There are now several highly integrated platforms that can guide the data scientist/engineer through the maze of challenges to deploying a successful ML solution to a business or scientific problem.
Interesting examples of MlOps tools include
- Algorithmia – originally a Seattle startup building an “algorithmic services platform” which evolved into a full MlOps system capable of managing the full ML management lifecycle. Algorithmia was acquired by DataRobot and is now widely used.
- Metaflow is an open source MLOps toolkit originally developed by Netflix. Metaflow uses a directed acyclic graph to encode the steps and manage code and data versioning.
- Polyaxon is a Berlin based company that is a “Cloud Native Machine Learning Automation Platform.”
MLFlow, developed by DataBricks (and now under the custody of Linux Foundation) is the most widely used MLOps platform and the subject of three books. The one reviewed here is “Practical Deep Learning at Scale with MLFlow” by Dr. Yong Liu. According to Dr. Liu, the deep learning life cycle consists of
- Data collection, cleaning, and annotation/labeling.
- Model development which is an iterative process that is conducted off-line.
- Model deployment and serving it in production.
- Model validation and online testing done in a production environment.
- Monitoring and feedback data collection during production.
MLFlow provides the tools to manage this lifecycle. The book is divided into five sections that cover these items in depth. The first section is where the reader is acquainted with the basic framework. The book is designed to be hands-on with complete code examples for each chapter. In fact about 50% of the book is leading the reader through this collection of excellent examples. The up-side of this approach is that the reader becomes a user and gains expertise and confidence with the material. Of course, the downside (as this author has learned from his own publications) is that software evolves very fast and printed versions go out of date quickly. Fortunately, Dr. Liu has a GitHub repository for each chapter that can keep the examples up to date.
In the first section of the book, we get an introduction to MLFlow. The example is a simple sentiment analysis written in PyTorch. More precisely it implements a transfer learning scenario that highlights the use of lightning flash which provides a high level set of tools that encapsulate standard operations like basic training, fine tuning and testing. In chapter two, MLFlow is first introduced as a means to manage the experimental life cycle of model development. This involves the basic steps of defining and running the experiment. We also see the MLFlow user portal. In the first step the experiment is logged with the portal server which records the critical metadata from the experiment as it is run.
This reader was able to do all of the preceding on a windows 11 laptop, but for the next steps I found another approach easier. Databricks is the creator of MLFlow, so it is not surprising that MLFlow is fully supported on their platform. The book makes it clear that the code development environment of choice for MLOps is not my favorite Jupyter, but rather VSCode. And for good reasons. VSCode interoperates with MLFlow brilliantly when running your own copy of MLFlow. If you use the Databricks portal the built-in notebook editor works and is part of the MLFlow environment. While Databricks has a free trial account, many of the features describe below are not available unless you have an account on AWS or Azure or GCS and a premium Databrick account.
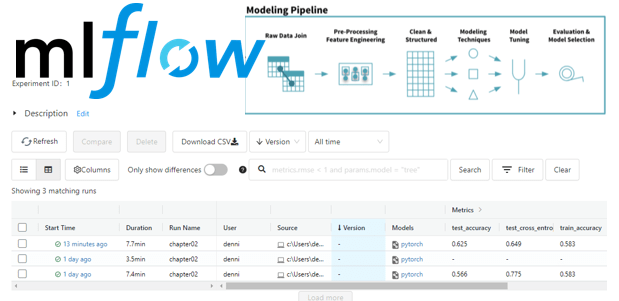
One of the excellent features of MLFlow is its ability to track code versioning data and pipeline tracking. As you run experiments you can modify the code in the notebook and run it again. MLFlow keeps track of the changes, and you can return to previous versions with a few mouse clicks (see Figure 1).

Figure 1. MLFlow User Interface showing a history of experiments and results.
Pipelines in MLFlow are designed to allow you to capture the entire process from feature engineering through model selection and tuning (See Figure 2). The pipelines consider are data wrangling, model build and deployment. MLFlow supports the data centric deep learning model using Delta Lake to allow versioned and timestamped access to data.

Figure 2. MLFlow pipeline stages illustration. (From Databricks)
Chapter 5 describes the challenges of running at scale and Chapter 6 takes the reader through hyperparameter tuning at scale. The author takes you through running locally with a local code base and then running remote code from Github and finally running the code from Github remotely on as Databricks cluster.
In Chapter 7, Dr Liu dives into the technical challenge of hyperparameter optimization (HPO). He compares three sets of tools for doing HPO at scale but he settles on Ray Tune which work very well with MLFlow. We have describe Ray Tune elsewhere in our blog, but the treatment in the book is much more advanced.
Chapter 8 turn to the very important problem of doing ML inference at scale. Chapter 9 provides an excellent, detailed introduction to the many dimensions of explainability. The primary tool discussed is based on SHapley Additive exPlanations (SHAP), but others are also discussed. Chapter 10 explores the integration of SHAP tools with MLFlow. Together these two chapters provide an excellent overview of the state of the art in deep learning explainability even if you don’t study the code details.
Conclusion
Deep learning is central to the concepts embodied in the notion that much of our current software can be generated or replaced entirely by neural network driven solutions. This is often called “Software 2.0’. While this may be an apocryphal idea, it is clear that there is a great need for tools that can help guide developers through the best practices and procedures for deploying deep learning solutions at scale. Dr Yong Liu’s book “Practical Deep Learning at Scale with MLFlow” is the best guide available to navigating this new and complex landscape. While much of it is focused on the MLFlow toolkit from Databricks, it is also a guide to concepts that motivate the MLFlow software. This is especially true when he discusses the problem of building deep learning models, hyperparameter tuning and inference systems at scale. The concluding chapters on deep learning explainability together comprise one of the best essays on this topic I have seen. Dr. Liu is a world-class expert on MLOps and this book is an excellent contribution.
