

Updated April 4, 1017. Much of this material has been updated and improved and now appears as Chapter 10, Cloud Computing for Science and Engineering. It can be accessed at the book’s website.
Update Nov 10, 2016. Microsoft now has a new release of CNTK. We have a post now that provides a quick look at this new version. Go read that one instead of this one.
Update Oct 25, 2016. this post describes the early version of CNTK. Microsoft just released a very nice new version called the cognitive toolkit. I would not base your impression of CNTK on the following post. I’ll update this as soon as I have time.
———————–
CNTK is Microsoft’s Computational Network Toolkit for building deep neural networks and it is now available as open source on Github. Because I recently wrote about TensorFlow I thought it would be interesting to study the similarities and differences between these two systems. After all, CNTK seems to be the reigning champ of many of the image recognition challenges. To be complete I should also look at Theano, Torch and Caffe. These three are also extremely impressive frameworks. While this study will focus on CNTK and TensorFlow I will try to return to the others in the future. Kenneth Tran has a very nice top level (but admittedly subjective) analysis of all five deep learning tool kits here. This will not be a tutorial about CNTK or Tensorflow. Rather my goal is to give a high level feel for how they compare from the programmer’s perspective. This is not a performance analysis, but rather a programming model analysis. There is a lot of code here, so if you don’t like reading code, skip to the conclusions.
CNTK has a highly optimized runtime system for training and testing neural networks that are constructed as abstract computational graphs. In that sense, CNTK is very much like TensorFlow. However, there are some fundamental differences. To illustrate these features and differences I will take two standard examples that are included with both systems and work through the approach taken by each system. The first example is a not-too-deep convolutional neural net solution to the standard MNIST handwritten digit recognition example. I will conclude with some comments about how they differ in their approach in the case of recurrent neural networks.
Both TensorFlow and CNTK are basically script-driven. By this I mean that the construction of the neural network flow graph is described in a script and the training is done using some very clever automated processes. In the case of TensorFlow the script is embedded in the Python language and Python operators can be used to control the flow of execution of the computational graph. CNTK does not currently have a Python or C++ binding (though one is promised) so currently the control flow of the execution of the training and testing is highly choreographed. As I will show, this is not as much of a limitation as it sounds. There are actually two scripts associated with a CNTK network: a configuration file that controls the training and test parameters and a network definition language file for constructing the network.
I’ll start with the description of the neural network flow graph because that is where the similarity to TensorFlow is the greatest. There are two ways to define the network in CNTK. One approach is to use the “Simple Network Builder” that will allow you to create some simple standard networks by specifying only a few parameter settings. The other is to use their Network Definition Language (NDL). The example here (taken directly from their download package in Github) uses NDL. Below is a slightly abbreviated version of the Convolution.ndl file. (I have used commas to put multiple lines on one line to fit the page better.)
CNTK network graphs have a set of special nodes. These are FeatureNodes and LabelNodes that describe the inputs and training labels, CriterionNodes and EvalNodes that that are used for training and result evaluation, and OutputNodes that represent the outputs of the network. I will describe these below as we encounter them. At the top of the file we have a set of macros that are used to load the data (features) and labels. As can be seen below we read images of the MNIST digits as features which are now arrays of floating point numbers that we have scaled by a small scalar constant. The resulting array “featScaled” will be used as input to the network.
load = ndlMnistMacros
# the actual NDL that defines the network
run = DNN
ndlMnistMacros = [
imageW = 28, imageH = 28
labelDim = 10
features = ImageInput(imageW, imageH, 1)
featScale = Const(0.00390625)
featScaled = Scale(featScale, features)
labels = Input(labelDim)
]
DNN=[
# conv1
kW1 = 5, kH1 = 5
cMap1 = 16
hStride1 = 1, vStride1 = 1
conv1_act = ConvReLULayer(featScaled,cMap1,25,kW1,kH1,hStride1,vStride1,10, 1)
# pool1
pool1W = 2, pool1H = 2
pool1hStride = 2, pool1vStride = 2
pool1 = MaxPooling(conv1_act, pool1W, pool1H, pool1hStride, pool1vStride)
# conv2
kW2 = 5, kH2 = 5
cMap2 = 32
hStride2 = 1, vStride2 = 1
conv2_act = ConvReLULayer(pool1,cMap2,400,kW2, kH2, hStride2, vStride2,10, 1)
# pool2
pool2W = 2, pool2H = 2
pool2hStride = 2, pool2vStride = 2
pool2 = MaxPooling(conv2_act, pool2W, pool2H, pool2hStride, pool2vStride)
h1Dim = 128
h1 = DNNSigmoidLayer(512, h1Dim, pool2, 1)
ol = DNNLayer(h1Dim, labelDim, h1, 1)
ce = CrossEntropyWithSoftmax(labels, ol)
err = ErrorPrediction(labels, ol)
# Special Nodes
FeatureNodes = (features)
LabelNodes = (labels)
CriterionNodes = (ce)
EvalNodes = (err)
OutputNodes = (ol)
]
The network is defined in the block DNN. The network consists of two convolutional-maxpooling layers followed by an all-to-all standard network with one hidden later of 128 nodes.
In convolutional layer one we have 5×5 convolutional kernels and we specify 16 of these (cMap1) for the parameter space. The operator ConvReLULayer is actually a shorthand for another subnetwork defined in a macro file.
Algebraically we would like to represent the parameters of the convolution as a matrix W and a scale vector B so that if the input is X, the output of our network layer is of the form output = f(op(W, X) + B). In this case the operator op is convolution and f is the standard relu function relu(x)=max(x,0).
The NDL code for the ConvReLULayer is given by
ConvReLULayer(inp, outMap, inWCount, kW, kH, hStride, vStride, wScale, bValue) =
[
convW = Parameter(outMap, inWCount, init="uniform", initValueScale=wScale)
convB = Parameter(outMap, 1, init="fixedValue", value=bValue)
conv = Convolution(convW, inp, kW, kH, outMap, hStride,vStride,
zeroPadding=false)
convPlusB = Plus(conv, convB);
act = RectifiedLinear(convPlusB);
]
The W matrix and B vector are defined as Parameters and they will be the entities that are given an initial value and then modified during training to define the final model. In this case convW is a matrix with 16 rows of 25 columns B is a scale vector of length 16. Convolution is a built-in function that has been set to not use zero padding. This means that convolution over the 28×28 image will be centered on the 24 by 24 interior region and the result will be 16 variations of a 24×24 output sudo-image.
We next apply Maxpooling based on 2×2 regions and the result is now 12×12 by 16.
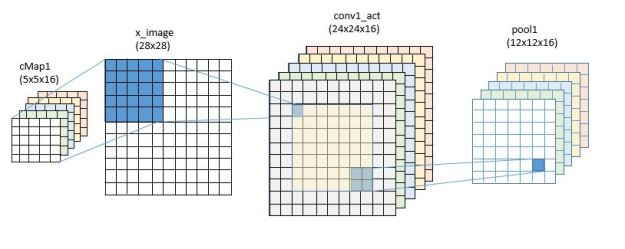
For the second convolutional layer we up the number of convolutional filters from 16 to 32. This time we have 16 channels of input so the size of the W matrix is 32 rows of 25×16 = 400 and the B vector for this layer is 32 long. The convolution is now over the interior of the 12×12 frames so it is size 8×8 and we have 32 copies. The second maxpooling step takes us to 32 frames of 4×4 or a result of size 32*16 = 512.
The final layers have the 512 maxpooling output and a hidden layer of 128 nodes to a final 10 node output defined by the two operators
DNNSigmoidLayer(inDim, outDim, x, parmScale) = [
W = Parameter(outDim, inDim, init="uniform", initValueScale=parmScale)
b = Parameter(outDim, 1, init="uniform", initValueScale=parmScale)
t = Times(W, x)
z = Plus(t, b)
y = Sigmoid(z)
]
DNNLayer(inDim, outDim, x, parmScale) = [
W = Parameter(outDim, inDim, init="uniform", initValueScale=parmScale)
b = Parameter(outDim, 1, init="uniform", initValueScale=parmScale)
t = Times(W, x)
z = Plus(t, b)
]
As you can see these are defined by the standard linear algebra operators as W*x+b.
The final part of the graph definition is the cross entropy and error nodes followed by a binding of these to the special node names.
We will define the training process soon, but first it is fun to compare this to the construction of a very similar network in TensorFlow. We described this in a previous post but here it is again. Notice that we have the same set of variables as we did with CNTK except they are called variables here and parameters in CNTK. The dimensions are also slightly different. The convolutional filters 5×5 in both cases but we have 16 copies in the first stage and 32 in the second in CNTK and 32 in stage one and 64 in stage two in the TensorFlow example.
def weight_variable(shape, names): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial, name=names) def bias_variable(shape, names): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial, name=names) x = tf.placeholder(tf.float32, [None, 784], name="x") sess = tf.InteractiveSession() W_conv1 = weight_variable([5, 5, 1, 32], "wconv") b_conv1 = bias_variable([32], "bconv") W_conv2 = weight_variable([5, 5, 32, 64], "wconv2") b_conv2 = bias_variable([64], "bconv2") W_fc1 = weight_variable([7 * 7 * 64, 1024], "wfc1") b_fc1 = bias_variable([1024], "bfcl") W_fc2 = weight_variable([1024, 10], "wfc2") b_fc2 = bias_variable([10], "bfc2")
The network construction is also almost identical.
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
#first convolutional layer
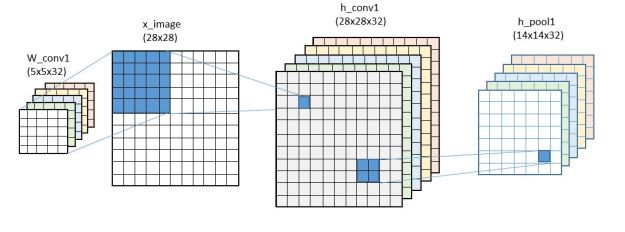
x_image = tf.reshape(x, [-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
#second convolutional layer
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#final layer
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
The only differences are that the convolutional operators here are defined with padding so the output of the first convolutional operator had dimensions of 28 by 28 flowed by a pooling reduction to 14 by 14. The second convolutional operator and max pooling reduces this to 7×7, so the input to the final layer is 7x7x64 = 3136 with 1024 hidden nodes (with a relu instead of a sigmoid function). (For training purposes the last stage uses a probabilistic dropout function that randomly set values to zero. If keep_prob = 1, this is a no-op. )
Network Training
The way network training is specified in CNTK differs substantially from the TensorFlow approach. The training and testing is specified in a file called convolution.config. Both CNTK and TensorFlow use a symbolic analysis of the flow graph to compute the gradient of the network for use in gradient decent training algorithms. The CNTK team has a very nice “book” that describes a great deal about how the gradients are computed. Currently CNTK only supports one learning method: Mini-batch Stochastic Gradient Decent, but they promise to add more in the future. He, Zhang, Ren and Sun have a lovely paper that describes how they train extremely deep (up to 1000 layers) networks using a nested residual reduction method reminiscent of algebraic multi-grid, so it will be interesting to see if that method makes its way into CNTK. An abbreviated version of the config file is shown below.
command = train:test
modelPath = "$ModelDir$/02_Convolution"
ndlMacros = "$ConfigDir$/Macros.ndl"
train = [
action = "train"
NDLNetworkBuilder = [
networkDescription = "$ConfigDir$/02_Convolution.ndl"
]
SGD = [
epochSize = 60000
minibatchSize = 32
learningRatesPerMB = 0.5
momentumPerMB = 0*10:0.7
maxEpochs = 15
]
reader = [
readerType = "UCIFastReader"
file = "$DataDir$/Train-28x28.txt"
features = [
dim = 784
start = 1
]
labels = [
# details deleted
]
]
]
test = [
….
]
The command line indicates the sequence to follow: train then test. Various file paths are resolved and then the train block specifies the network to be trained and the parameters for the Stochastic Gradient Decent (SGD). A reader block specifies the way the “features” and “labels” from the network NDL file are read. A test block is also included to define the parameters of the test.
Running this on a 16-core (non-GPU) linux VM took 62.95 real-time minutes to do the train and test and 999.01 minutes of user time and 4 minutes of system time. The user time indicated that all 16 cores were all very busy (999/63 = 15.85). Of course this means little as CNTK is designed for parallelism and massive GPU support is the true design point idea.
The training used by TensorFlow is specified much more explicitly in the Python control flow. However, the algorithm is also a gradient based method called Adam introduced by Kingma and Ba. Tensorflow has a number of gradient based optimizers in the library, but I did not try any of the others.
As can be seen below, the cross_entropy is defined in the standard way and fed to the optimizer to produce a “train_step” object.
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.initialize_all_variables())
for i in range(20000):
batch = mnist.train.next_batch(50)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
Then for 20000 iterations the python program grabs a batch of 50 and runs the train_step with 50% random dropout. The test step is to evaluate the accuracy subgraph on the entire test set.
Aside from the magic of the automatic differentiation and the construction of the Adam optimizer trainer, this is all very straightforward. I also ran this on the same 16 core server with the same data as was used for the CNTK case. Much to my surprise the real time was almost exactly the same as CNTK. The real time was 62.02 minutes, user time 160.45 min, so much less parallelism was exploited. I don’t believe these numbers mean much. Both CNTK and Tensor flow are designed for large scale GPU execution and they are not running exactly the same training algorithm.
Recurrent Neural Nets with CNTK and TensorFlow
Recurrent Neural Networks (RNNs) are widely used in language modeling such as predicting the next word you are going to type when texting or in automatics translation systems. (see Andrej Karpathy’s blog for some great examples.) It is really a lovely idea. The input to the system is a word (or set of words) along with the state of the system based on words seen so far and the output is a predicted word list and a new state of the system as shown in Figure 1.
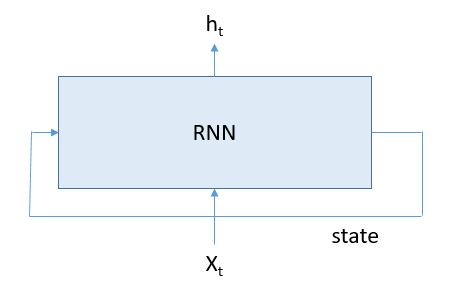
Figure 1.
There are, of course, many variations of the basic RNN. One of the most popular is the Long-Short Term Memory (LSTM) version that is defined by the equations
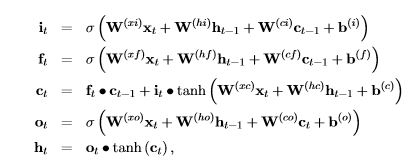
Figure 2. LSTM Equations (taken from the CNTK book)
where ![]() is the sigmoid function.
is the sigmoid function.
If you want to read a great blog article about LSTMs and how they work, I recommend this one by Christopher Olah. In fact, he has a diagram that makes it a bit easier to see the flow of the equations above. I had to modify it a tiny bit to fit the CNTK version of the equations and the result is shown in Figure 3.
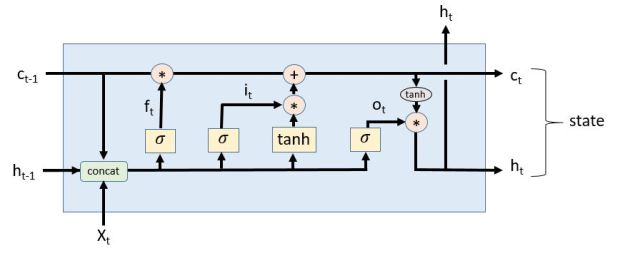
Figure 3. Adapted from Christopher Olah’s excellent article.
The notation in the picture uses sigmoid and tanh boxes and concatenated variables to represent this expression.
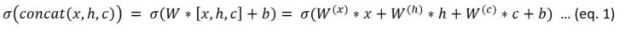
As can be seen, this is the form of the equations in figure 2 where the Ws and the bs are the learned weights.
CNTK version
Below is the network definition language specification for the LSTM graph. There are two things to notice here. The first is the way the recurrence is handled directly in the network using a delay operator called “PastValue” that takes variable, its dimension and a time delay value and returns a buffered copy of that value. The second thing to see is the way the W matrix is handled and how it differs from our concatenated operator describe above and in Figure 3. Here they “stack” all the Ws that belong to x and all the Ws that belong to h and a stack of b values. They then compute one W*x and one W*h and add them and then add b. They then use a row slice operator to pull them apart to be used in the separate sigmoid functions. Also note that they use the fact the Ws for c are all diagonal matrices.
LSTMPComponent(inputDim, outputDim, cellDim, inputx, cellDimX2, cellDimX3, cellDimX4) = [
wx = Parameter(cellDimX4, inputDim, init="uniform", initValueScale=1);
b = Parameter(cellDimX4, 1, init="fixedValue", value=0.0);
Wh = Parameter(cellDimX4, outputDim, init="uniform", initValueScale=1);
Wci = Parameter(cellDim, init="uniform", initValueScale=1);
Wcf = Parameter(cellDim, init="uniform", initValueScale=1);
Wco = Parameter(cellDim, init="uniform", initValueScale=1);
dh = PastValue(outputDim, output, timeStep=1);
dc = PastValue(cellDim, ct, timeStep=1);
wxx = Times(wx, inputx);
wxxpb = Plus(wxx, b);
whh = Times(wh, dh);
wxxpbpwhh = Plus(wxxpb,whh)
G1 = RowSlice(0, cellDim, wxxpbpwhh)
G2 = RowSlice(cellDim, cellDim, wxxpbpwhh)
G3 = RowSlice(cellDimX2, cellDim, wxxpbpwhh);
G4 = RowSlice(cellDimX3, cellDim, wxxpbpwhh);
Wcidc = DiagTimes(Wci, dc);
it = Sigmoid (Plus ( G1, Wcidc));
bit = ElementTimes(it, Tanh( G2 ));
Wcfdc = DiagTimes(Wcf, dc);
ft = Sigmoid( Plus (G3, Wcfdc));
bft = ElementTimes(ft, dc);
ct = Plus(bft, bit);
Wcoct = DiagTimes(Wco, ct);
ot = Sigmoid( Plus( G4, Wcoct));
mt = ElementTimes(ot, Tanh(ct));
Wmr = Parameter(outputDim, cellDim, init="uniform", initValueScale=1);
output = Times(Wmr, mt);
]
The TensorFlow version
The TensorFlow version of the LSTM recurrent neural network is very different from the CNTK version. While they both execute the same underling set of equations the way it is represented in TensorFlow make strong use of the Python control flow. The conceptual model is simple. We create a LSTM cell and define a “state” which is input to the cell and also an output. In pseudo code:
cell = rnn_cell.BasicLSTMCell(lstm_size)
# Initial state of the LSTM memory.
state = tf.zeros([batch_size, lstm.state_size])
for current_batch_of_words in words_in_dataset:
# The value of state is updated after processing each batch of words.
output, state = cell(current_batch_of_words, state)
This is a nice pseudo code version of figure 1 taken from the tutorial. The devil is in the very subtle details. Remember that most of the time python code in Tensor flow is about building the flow graph, so we have to work a bit harder to build the graph with the cycle that we need to train and execute.
It turns out that the greatest challenge is defining how we can create and reuse the weight matrices and bias vectors inside a graph with a cycle. CNTK uses the operator “PastValue” to create the needed cycle in the graph. TensorFlow uses the literal recurrence above and a very clever variable save and recall mechanism to accomplish the same thing. The moral equivalent of “PastValue” in Tensorflow is a function called tf.get_variable( “name”, size, initializer = None) whose behavior depends upon a flag called “reuse” associated with the current variable scope. If reuse==False and no variable already exists by that name in this scope then get_variable returns a new variable with that name and uses the initializer to initialize it. Otherwise it returns an error. If reuse == True then get_variable returns the previously existing variable by that name. If no such variable exists, it returns an error.
To illustrate how this is used below is a simplified version of one of the functions in TensorFlow used to create the sigmoid function from eq. 1 above. It is just a version of W*x+b where x is a list [a, b, c, …].
def linear(args, output_size, scope=None):
#Linear map: sum_i(args[i] * W[i]), where W[i] is a variable.
with vs.variable_scope(scope):
matrix = vs.get_variable("Matrix", [total_arg_size, output_size])
res = math_ops.matmul(array_ops.concat(1, args), matrix)
bias_term = vs.get_variable(
"Bias", [output_size],
initializer=init_ops.constant_initializer(1.))
return res + bias_term
Now to define the BasicLSTMCell we can write it roughly as follows. (To see the complete versions of these functions look at rnn_cell.py in the TensorFlow Github repository.)
class BasicLSTMCell(RNNCell):
def __call__(self, inputs, state, scope=None):
with vs.variable_scope(scope):
c, h = array_ops.split(1, 2, state)
concat = linear([inputs, h], 4 * self._num_units)
i, j, f, o = array_ops.split(1, 4, concat)
new_c = c * sigmoid(f) + sigmoid(i) * tanh(j)
new_h = tanh(new_c) * sigmoid(o)
return new_h, array_ops.concat(1, [new_c, new_h])
As you can see, this is a fairly accurate rendition of the diagram in Figure 3. You will notice the operator split above is the counterpart to the rowslice operation in the CNTK version.
We can now create instances of a recurrent neural network that can be used for training and using the same variable scope we can create another one to use for testing that share the same W and b variables. The way this is done is shown in ptb_word_lm.py in the TensorFlow tutorials for recurrent neural nets. There are two additional points worth observing. (I should say they were critical for me to understand this example.) They create a class lstmModel that can be used to build the networks for training and test.
class lstmModel:
def __init__(self, is_training, num_steps):
self._input_data = tf.placeholder(tf.int32, [batch_size, num_steps])
self._targets = tf.placeholder(tf.int32, [batch_size, num_steps])
cell = rnn_cell.BasicLSTMCell(size, forget_bias=0.0)
outputs = []
states = []
state = self._initial_state
with tf.variable_scope("RNN"):
for time_step in range(num_steps):
if time_step > 0:
tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(inputs[:, time_step, :], state)
outputs.append(cell_output)
states.append(state)
… many details omitted …
Where this is used is in the main program were we create a training instance and a test instance (actually there is a third instance which I am skipping to keep this as simple as possible).
with tf.variable_scope("model", reuse=None, initializer=initializer):
m = PTBModel(is_training=True, 20)
with tf.variable_scope("model", reuse=True, initializer=initializer):
mtest = PTBModel(is_training=False, 1)
What is happening here is that the instance m is created with 20 steps with no reuse initially. As you can see from the initializer above that will cause the loop to unroll 20 copies of the cell in the graph and after the first iteration the reuse flag is set to True, so all instances will share the same W and b. The training works on this unrolled version. The second version mtest has reuse = True and it only has one instance of the cell in the graph. But the variable scope is the same as m, so it shares the same trained variables as m.
Once trained, we can invoke the network with a kernel like the following.
cost, state = sess.run([mtest.cost, mtest.final_state],
{mtest.input_data: x,
mtest.targets: y,
mtest.initial_state: state})
Where x and y are the inputs. This is far from the complete picture of the tutorial example. For example, I have not gone into the training at all and the full example uses a stacked LSTM cell and a dropout wrapper. My hope is that the detail I have focused on here will help the reader understand the basic structure of the code.
Final Observations
I promised a programming model comparison of the two systems. Here are some top level thoughts.
- TensorFlow and CNTK are very similar for the simple convolutional neural network example. However, I found the TensorFlow version easier to experiment with because it is driven by python. I was able to load it as a IPython notebook and try different things. With CNTK one needed to completely understand how to express things with the configuration file. I found that difficult. With TensorFlow I was able to write a simple k-means clustering algorithm (see my previous post on Tensorflow). I was unable to do this with CNTK and that may be due to my cluelessness rather than a limit of CNTK. (If somebody knows how to do it, I would appreciate a tip.)
- In the case of the LSTM recurrent neural network, I found the CNTK version to be completely transparent. In the case of Tensorflow I found the top level idea very elegant, but I also found it very difficult to understand all the details because of the clever use of the variable scoping and variable sharing. I had to dig very deep to understand how it worked. And it is not clear that I have it all yet! I did find one trivial bug in the Tensorflow version that was easy to fix and I am not convinced that the variable scoping and reuse flags, which are there to solve an encapsulation problem, are the best solutions. But the good think about TensorFlow is that I can easily experiment with alternatives.
- I must also say that the CNTK book and the TensorFlow tutorials are both excellent introductions to the high level concepts. I am sure more detailed, deep-dive books will come out soon.
I am also convinced that as both systems mature they will improve and become easier to program. I did not discuss performance, but CNTK is the current champ in terms of speed on some difficult challenges. But with the rapid evolution of these systems I expect to see the competition to heat up.
