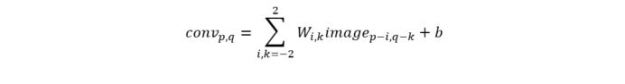When I was (very) young I enjoyed building electronic devices from kits and from wiring diagrams I found in exciting journals like “Popular Electronics”. Radio Shack was my friend and Heath Kits were a joy when I could afford them. Today I marvel at the devices kids can tinker with. They can build Arduino powered Lego robots that are lightyears beyond my childhood Lincoln Logs and Erector Sets. And they have access to another relatively recent, world changing technology: they have the ability to create software that brings their creations to life. They can add sensors (accelerometers, GPS, altimeters, thermometers, gyroscopes, vibration, humidity and more) to their projects as well as actuators and motors of various types. And these creations can live on the Internet. Devices like the Particle (formerly Spark) Photon and Electron IoT include WiFi or cellular links so instruments can send data to the cloud. They are programmed with the same C-like language used by the Arduino. Photon devices are extremely small and very inexpensive so they can be deployed in very large numbers.
Indeed, these devices are the atomic particles of the Internet of Things (IoT). They are being turned into modestly built home safety sensors as well as sophisticated instruments that control highly sensitive scientific experiments. They will be the tools city planners will use to understand our complex urban environments. For example, the Array of Things project at the University of Chicago and Argonne Labs is deploying an amazing small sensor pack on that will sit on light polls throughout the city. (Check out this video.) Charlie Catlett and Pete Beckman are leading the AoT project. In discussions with Charlie he told me that he has built a full array of sensors in his home to monitor various devices. He also pointed me to the Mathworks Thingspeak product which provides a lovely Matlab-based cloud platform for integrating and analyzing the streams of data from your instruments.
In a previous post I described ways in which event data could be streamed to the cloud and I will return to that topic again in the future. In this article I wanted to look at what could be done with a small device with a video camera when it was combined with analysis on the Cloud. I chose the Raspberry Pi2 and the cloud services from the new Microsoft Research project Oxford services.
Phone Apps and Project Oxford
While the instruments described above will eventually dominate the Internet of Things, the billions of smart phones out there today give us a pretty good idea of the challenge of managing data from sensors. Almost every truly useful “App” on a smart phone interacts services in the cloud in order to function properly. And each of these apps does part of its computation locally and part takes place remotely. Cortana and Siri can do the speech to text translation by invoking a speech model on the phone but answering the query involves another set of models running in the cloud. For any interesting computational task, including the tasks assigned to the Array of Things sensors, some computation must be done locally and some must be remote. In some cases, the local computation is needed to reduce the amount of time spent communicating with the back end services and in other cases, for example for privacy reasons, not all locally collected information should be transmitted to the cloud. (What happens to my phone in Vegas, should stay in Vegas.) Indeed, according to Catlett and Beckman, protecting privacy is a prime directive of the Array of Things project.
Companies like Amazon, Google, IBM, Microsoft and Salesforce have been working hard to roll out data analytics services hosted on their cloud platforms. More recently these and other companies have been providing machine learning services in the cloud. I have already talked about AzureML, a tool that allows you to build very powerful analysis tools, but for people who want to build smart apps there are now some very specialized services that do not require them to be ML domain experts. A good example is IBMs Watson Services that is a result of IBM’s work on bringing their great Jeopardy playing capability to a much broader class of applications. Watson has a great collection of language and speech analysis and translation services. In addition, it has an impressive collection of image analysis tools.
Project Oxford is another interesting collection of cloud services that cover various topics in computer vision, speech and language. In the area of speech, they provide the APIs needed for speech to text and text to speech. We are all familiar with the great strides taken in speech recognition with Siri, Cortana, Echo and others. With these APIs one can build apps for IOS, Windows and Android that use speech recognition or speech generation. The language tools include spell checkers, a nifty language understanding tool that you can train to recognize intent and action from utterances such as commands like “set an alarm for 1:00 pm.” The computer vision capabilities include scene analysis, face recognition, and optical character recognition (OCR). These are the services I will explore below.
Raspberry Pi2 and the OpenCV computer vision package.
The Raspberry Pi 2 is a very simple, credit card sized, $35 single board computer with a very versatile collection of interfaces. It has a Broadcom VideoCore GPU and a quad-core ARMv7 processor and 1 GB of memory. For a few extra dollars you can attach a five-megapixel camera. (In other words, it is almost as powerful as a cellphone.) The Pi2 device can run Windows 10 IoT Core or a distribution of Linux. I installed Linux because it was dead easy. To experiment with the camera, I needed the OpenCV computer vision tools. Fortunately, Adrian Rosebrock has documented the complete installation process in remarkable detail. (His book also provides many useful coding example that I used to build my experiments.)
Object Tracking
One of the most obvious sensing challenges one can tackle with a small Interconnected device with a camera is object tracking. With OpenCV there are some very sophisticated ways to do this, but for some tasks it is trivial. Outside my window there is a small harbor and I decided to track the movements of the boats. This was easy because they are all pleasure boats so the vast majority of them are white. By filtering the image to bring out white objects on a black background the OpenCV functions “findContours” and “minAreaRect” it requires only a few lines of code to draw bounding boxes around suspected boats. (Full source code for the examples here are in Github.) With the Pi device and camera sitting near the window. I was able to capture the scene below in Figure 1. Note that it took some scene specific editing. Specifically, it was necessary to ignore contours that were in the sky. As can be seen some objects that were not boats were also selected. The next step is to filter based on the motion of the rectangles. Those are the rectangles worth tracking. Unfortunately, being winter these pleasure craft haven’t moved for a while, so I don’t have a video to show you.

Figure 1. Using OpenCV to find boats in a harbor
Face Recognition
By face recognition we mean identifying those elements in a picture that are human faces. This is a far lower bar than face identification (who is that person?), but it is still an interesting problem and potentially very useful. For example, this could be used to approximate the number of people in a scene if you know what fraction of them are facing the camera. Such an approximation may be of value if you only wanted to know the density of pedestrian traffic. You could avoid privacy concerns because you would not need to save the captured images to non-volatile storage. It is possible to use OpenCV alone to recognize faces in a picture and never send the image outside the device.
If you do want to know more information about a group of people project Oxford can do much better. Given an image of a group it can identify the faces looking in the general direction of the camera and for each face it can give a number of interesting features such as gender, estimated age and even a “smile” index. This information may be of interest to a business, such as a movie theater owner who wants to know the gender makeup and average age of the of the patrons. It could even tell by counting smiles if they enjoyed the movie. I used project Oxford to do an analysis of two photos. The first is our class of amazing students and staff from the 2014 MSR summer school in Moscow. The vision service also returned a rectangle enclosing each face. I use OpenCV to draw the rectangle with a pink border for the males and green for females if they were smiling. If they were not smiling, they got a black rectangle. As can be seen, the reporting was very accurate for this staged group photo.

Figure 2. Project Oxford Face Recognition of MSR Summer School 2014 group photo taken at Yandex headquarters Moscow. Pink = male, green = female, black = no smile
The system also allowed us to compute estimated average age: approximately 21 for females, 24 for males. (Some “senior” professors in the photo skewed the average for males.). Figure 3 below shows the result for a stock street scene. Very few smiling faces, but that is not a surprise. It also illustrates that the system is not very good at faces in partial or full profile.

Figure 3. Many faces missing in this crowd, but one is smiling.
Text Recognition
Optical Character Recognition (OCR) has been around for use in document scanners for a long time but it is much harder to read text when it is embedded in a photo with other objects around it. For example, programing the Pi using a call to oxford OCR and pointing the camera at the image in Figure 4 produced the output in the superimposed rectangle (superimposition done with PowerPoint … not OpenCV).
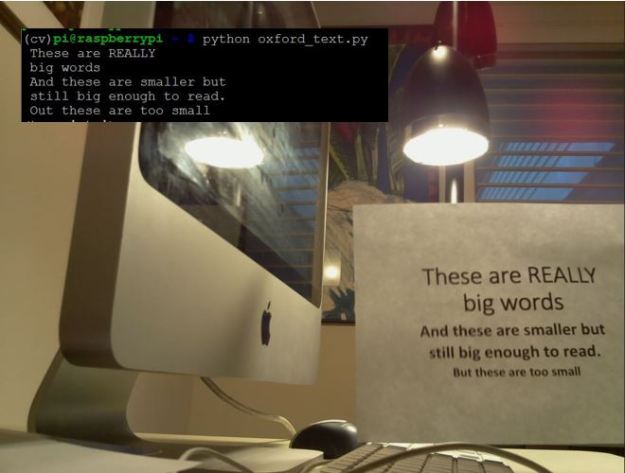
Figure 4. Oxford OCR test from Pi with command line output in black rectangle.
As can be seen, this was an easy case and it made only one error. However, it is not hard to push the OCR system beyond its limits based on distance, lighting and the angle of the image.
To demonstrate the power of doing some computation on the local device and some of it remotely in the cloud, we can take an scene that is too hard for oxford to understand directly and so some preprocessing with OpenCV. In Figure 5 we have taken a scene with the same piece of paper with text and placed it far from the camera and at a funny angle. This yielded no result with Oxford OCR directly. But in this case we used the same filtering technique used in the boat tracking experiment and located the rectangle containing the paper. Using another OpenCV transformation we transformed that rectangle into a 500 by 300 image with the rotation removed (as shown in the insert). We sent that transformed image to Oxford and got a partial result (shown in the black rectangle).

Figure 5. Transformed image and output showing the coordinates of the bounding rectangle and output from Oxford OCR. The green outline in the picture was inserted by OpenCV drawing functions using the bounding rectangle.
This experiment is obviously contrived. How often do you want to read text at a distance printed on a white rectangle? Let’s look at one final example below.
Judging a Book by Its Cover
An amusing App that may be able to use the Oxford OCR would be to use it to find information about a book based on an image of the cover. Of course, this is not a new idea. Amazon has an app called “Flow” from their A9 Innovations subsidiary. More on that later. What I did was to integrate Oxford OCR with a call to Bing. It works as follows. The Pi is shown the image of a book, the OCR app looks for text on the image like the title or author. Then that returned string is sent to Bing via a web service call. The top five results are then put into an HTML document along with the image and served up by a tiny webserver on the PI. The first results are shown below.
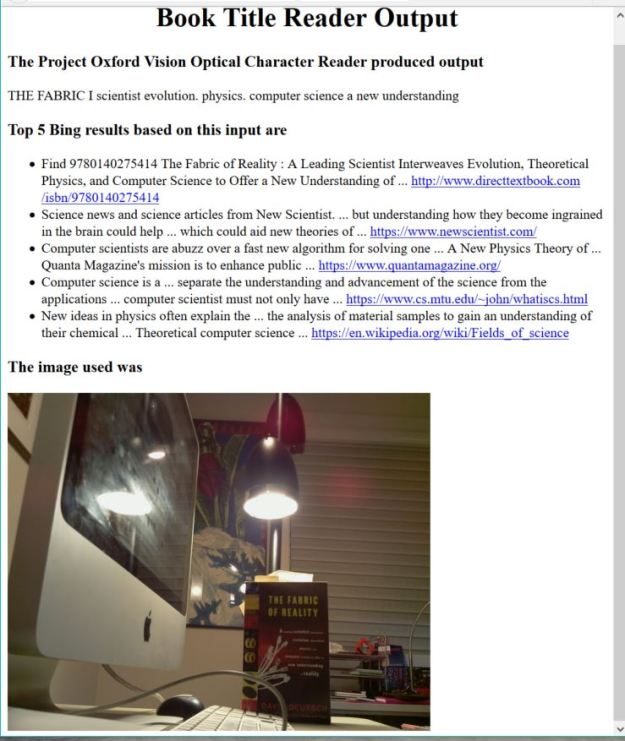
Figure 6. Output of the book cover reader app webserver on the PI. The first result is correct.
The interesting thing about this is that Bing (and I am sure Google as well) is powerful enough to take partial results from the OCR read and get the right book on the top hit. The correct text is
“The Fabric of Reality. A leading scientist interweaves evolution, theoretical Physics and computer science to offer a new understanding of reality.” (font changes are reproduced as shown on the book cover)
What the OCR systems was able to see was “THE FABRIC I scientist evolution, physics. Computer science a new understanding.” The author’s name is occluded by a keyboard cable.
Unfortunately, the reliability at a distance was not great. I next decided to try to enhance the image using the technique used in the “text on white rectangle” as illustrated in Figure 5. Of course this needed a white book, so it is not really practical. However, the results did improve the accuracy (for white books). An example that the OCR-only version failed to recognize but that worked using the OpenCV enhanced version is shown in Figure 7.

Figure 7. Using OpenCV with Oxford and Bing.
As can be seen the OCR saw “the black sivan nassim aicholas tal”, which is not very accurate. Even with the lower right corner of the book out of the image I would have expected it to do a bit better. But Bing was easily able to figure it out.
I downloaded the Flow app and installed it on a little Android tablet. It works very well up close but it could not handle the distance shots illustrated above. Of course this is not a proper scientific comparison. Furthermore, I have only illustrated a few trivial features of OpenCV and I have not touch the state-of-the-art object recognition work. Current object recognition systems based on deep learning are amazingly accurate. For example, MSR’s Project Adam was used to identify thousands of different types of object in images (including hundreds of breeds of dogs). I expect that Amazon has the images of tens of thousands of book covers. A great way to do the app above would be to train a deep network to recognize those objects in an image. I suspect that Flow may have done something like this.
Final Thoughts
The examples above are all trivial in scope, but they are intended to illustrate what one can do with a very simple little device, a few weeks of programming and access to tools like Project Oxford. We started with a look at IoT technologies and moved on to simple “apps” that use computer vision. This leads us to think about the topic of augmented reality where our devices are able to tell us about everything and everyone around us. The “everyone” part of this is where we have the most difficulty. I once worked on a project called the “intelligent memory assistant”. Inspired by a comment from Dave Patterson, the app would use a camera and the cloud to fill in the gaps in your memory so that when you met a person but could not remember their name or where they were from. It would whisper into your ear and tell you “This is X and you knew him in 1990 …. “. It is now possible to build this, but the privacy issues raise too many problems. It is sometime referred to as the “creepy factor”. For example, people don’t always want to be “tagged” in a photo on Facebook. On the other hand uses like identifying lost children or amnesiacs are not bad. And non-personal components of augmented reality are coming fast and will be here to stay.
PS Code for these examples is now in this github repo