
NOTE: This is a revised version of this blog that reflects much better ways to do some of the tensor algebra in the first example below.
Google has recently released some very interesting new tools to the open source community. First came Kubernetes, their container microservice framework, and that was followed by two new programming systems based on dataflow concepts. Dataflow is a very old idea that first appeared in the computer architecture community in the 1970 and 80s. Dataflow was created as an alternative to the classical von-Neumann computer design. It was hoped that it would have a performance advantage because it would exploit much greater levels of parallelism than thought possible with classical computers[1]. In dataflow systems computation can be visualized as a directed graph where the vertices of the graph are operators and data “flows” through the system along the edges of the graph. As soon as data is available on all the input edges of an operator node the operation is carried out and new data is put on the output edges of the node. While only a few actual data flow computers were built, the concept has been fundamental to distributed and parallel computing for a long time. It shows up in applications like complex event processing, stream analytics and systems like the Microsoft AzureML programming model I described earlier.
Google’s newly released Cloud Dataflow is a programming system for scalable stream and batch computing. I will return to Cloud Dataflow in another post, but for now, I will focus on the other dataflow system they released. Called TensorFlow, it is a programming system designed to help researchers build deep neural networks[2] and it appears to be unrelated to Cloud Dataflow. All the documentation and downloadable code for TensorFlow are on-line. TensorFlow is also similar to Microsoft Research’s Computational Network Toolkit (CNTK) in several ways that I will describe later.
TensorFlow is designed allow the programmer to easily “script” a dataflow computation where the basic units of computing are very large multi-dimensional arrays. The scripts are written in Python or C++ and it works very well with IPython/jupyter notebooks. In the following pages I will give a very light introduction to TensorFlow programming and illustrate it by building a bare-bones k-means clustering algorithm. I will also briefly describe one of their examples of a convolutional neural network.
TensorFlow can be installed and run on your laptop, but as we shall show below, it really shines on bigger more powerful hardware. An interesting thing happened in the recent evolution of deep neural networks. The most impressive early work on really large deep neural network was done on large cloud-scale clusters. However, the type of parallelism needed for doing deep network computation was really very large array math, which is really better suited to execution on a GPU. Or a bunch of GPUs on a massive memory machine or a cluster of massive memory machines with a bunch of GPUs each. For example, the Microsoft CNTK has achieved some remarkable results on 8 GPU systems and it will soon be available on the Azure GPU Lab. (I also suspect that supercomputers such as the SDSC Comet with large memory, multi-GPU, multi-core nodes would be ideal.)
TensorFlow: a shallow introduction.
There is a really nice white paper by the folks at Google Research with far more details about the TensorFlow system architecture than I give here. What follows is a shallow introduction and an experiment.
There are two main concepts in TensorFlow. The first is the idea of computing on objects that are very large multi-dimensional arrays called tensors. The second is the fact that the computation you build with tensors are compiled into graphs that are executed in a “dataflow” style. We need to unpack both of these concepts.
Tensors
Let’s start with tensors. First, these are not your great-great grandfather’s tensors. Those tensors were introduced by Carl Friedrich Gauss for differential geometry where they were needed to provide metrics that could be used to describe things like the curvature of surfaces. Einstein “popularized” tensors in his general theory of relativity. Those tensors have a very formal algebra of covariant and contravariant forms. Fortunately, we don’t have to go there to understand the use of tensors in TensorFlow’s machine learning applications. In fact, if you understand Numpy arrays you are off to a good start and Numpy arrays are just really efficient multidimensional arrays. TensorFlow can be programmed in Python or C++ and I will use the Python binding in the discussion below
In TensorFlow tensors are created and stored in container objects that are one of three types: variables, placeholders and constants. Let’s start with constants. As the name implies constant tensors are initialized once and never changed. Here are two different ways to create constant arrays that we will use in an example below. One is a tensor of size Nx2 filled with zeros and the other is a tensor of the same shape filled with the value 1.
import numpy as np import tensorflow as tf N = 10000 X = np.zeros(shape=(N,2)) Xv = tf.constant(X, name="points") dones = tf.fill([N,2], np.float64(1.))
We have used a Numpy array of values to create the TensorFlow constant. Notice that we have given our tensor a “name”. Naming tensors is optional but it comes in very handy when debugging.
Variables are holders of multidimensional arrays that persist across sessions and may be modified and even saved to disk. The concept of a “session” is important in TensorFlow. You can think of it as a context where actual TensorFlow calculations take place. The first calculation involving a variable is to load it with initial values. For example, let’s create a 2 by 3 tensor that, when initialized contains the constant 1.0 in every element. Then let’s convert that back to a Numpy array and print it. To do that we need a session and we will call the variable initializer in that session. When working in the IPython notebook it is easiest to use an “InteractiveSession” so that we can easily edit and redo computations.
sess = tf.InteractiveSession() myarray = tf.Variable(tf.constant(1.0, shape = [2,3])) init =tf.initialize_all_variables() sess.run(init) mynumpy =myarray.eval() print(mynumpy) [[ 1. 1. 1.] [ 1. 1. 1.]]
As shown above, the standard way to initialize variables is to initialize them all at once. The process of converting a tensor back to a Numpy array requires evaluating the tensor with the “eval” method. As we shall see this is an important operator that we will describe in more detail below.
The final tensor container is a “placeholder”. Creating a placeholder object only requires specifying a type and some information about its shape. We don’t initialize a placeholder like a variable because it’s initial values will be provided later in an eval()-like operation. Here is a placeholder we will use later.
x = tf.placeholder(tf.float32, [None, 784], name="x")
Notice that in this case the placeholder x is two dimensional but the first dimension is left unbound. This allows us to supply it with a value that is any number of rows of vectors of length 784. As we shall see, this turns out to be very handy for training neural nets.
Dataflow
The real magic of TensorFlow is in the dataflow execution of computations. A critical idea behind TensorFlow is to keep the slow world of Python away from the fast world of parallel tensor algebra as much as possible. Python is used only to describe the dataflow graph of the computation. TensorFlow has a large library of very useful tensor operators. Let’s describe a computation we will use in the k-means example. Suppose we have 8 points in the plane in a vector called Xv and 4 special points in an array called kPoints. I would like to label each of the 8 points with the index of the special point nearest to it. This should give me 4 clusters of points. I now want to find the centroid of each of these clusters. Assume we have a tensor called “blocked” where row i gives the distance from each of our 8 points to the ith special point. For example, if “blocked” is as shown below then what we are looking for is the index of the smallest element in each column.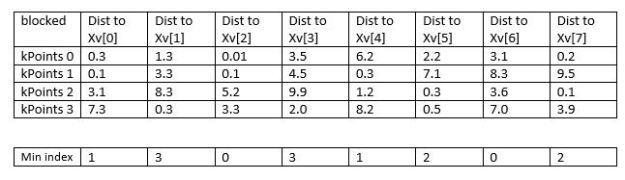
To find the centroids I use this min index vector to select the elements of Xv in each cluster. We just add them up to and divide by the number of points in that cluster. The TensorFlow code to do this is shown below. TensorFlow has a large and handy library of tensor operators many of which are similar to Numpy counterparts. For example, argmin computes the index of the smallest element in an array given the dimension over which to search. Unsorted_segment_sum will compute a sum using another vector to define the segments. The min index vector nicely partitions the Xv vector into the appropriate “segments” for the unsorted_segment_sum to work. The same unsorted_segment_sum operator can be used to count the number of elements in each cluster by adding up 1s.
mins = tf.argmin(blocked, 0, name="mins") sums = tf.unsorted_segment_sum(Xv, mins, 4) totals = tf.unsorted_segment_sum(dones, mins, 4, name="sums") centroids = tf.div(sums, totals, name = "newcents")
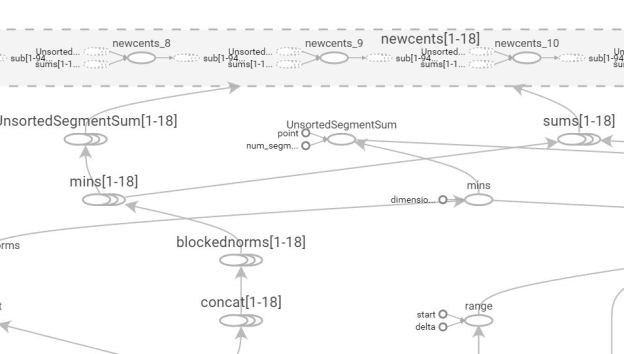
The key idea is this. When this python code is executed it builds a data flow graph with three inputs (blocked, Xv, dones) and outputs a tensor called centroids as shown below[3].[4]
The computation does not start until we attempt to evaluate the result with a call to centroids.eval(). This sort of lazy evaluation means that we can string together as many tensor operators as needed that will all be executed outside the Python REPL.

Figure 1. Computational flow graph
TensorFlow has a very sophisticated implementation. The computing environment upon which it is running is a collection of computational devices. These devices may be cpu cores, GPUs or other processing engines. The TensorFlow compilation and runtime system maps subgraphs of the flow graph to these devises and manages the communication of tensor values between the devices. The communication may be through shared memory buffers or send-receive message pairs inserted in the graph at strategically located points. Just as the dataflow computer architects learned, dataflow by itself is not always efficient. Sometimes control flow is needed to simplify execution. The TensorFlow system also inserts needed control flow edges as part of its optimizations. As was noted above, this dataflow style of computation is also at the heart of CNTK. Another very important property of these dataflow graphs is that it is relatively easy to automatically compute derivatives by using the chain-rule working backwards through the graph. This makes it possible to automate the construction of gradients that are important for finding optimal parameters for learning algorithms. I won’t get into this here but it is very important.
A TensorFlow K-means clustering algorithm
With the kernel above we now have the basis for a simple k-means clustering algorithm shown in the code below. Our initial centroid array is a 4 by 2 Numpy array we shall call kPoints. What is missing is the construction of the distance array blocked. Xv holds all the N points as a constant tensor. My original version of this program used python code to construct blocked. But there is an excellent improvement on computation of “mins” published in GitHub by Shawn Simister at. Shawn’s version is better documented and about 20% faster when N is in the millions. Simister’s computation does not need my blocked array and instead expands the Xv and centroids vector and used a reduction to get the distances. Very nice (This is the revision to the blog post that I referred to above.)
N = 10000000
k = 4
#X is a numpy array initialized with N (x,y) points in the plane
Xv = tf.constant(X, name="points")
kPoints = [[2., 1.], [0., 2.], [-1., 0], [0, -1.]]
dones = tf.fill([N,2], np.float64(1.))
centroids = tf.Variable(kPoints, name="centroids")
oldcents = tf.Variable(kPoints)
initvals = tf.constant(kPoints, tf.float64)
for i in range(20):
oldcents = centroids
#This is the Simister mins computation
expanded_vectors = tf.expand_dims(Xv, 0)
expanded_centroids = tf.expand_dims(centroids, 1)
distances = tf.reduce_sum( tf.square(
tf.sub(expanded_vectors, expanded_centroids)), 2)
mins = tf.argmin(distances, 0)
#compute the new centroids as the mean of the points nearest
sums = tf.unsorted_segment_sum(Xv, mins, k)
totals = tf.unsorted_segment_sum(dones, mins, k, name="sums")
centroids = tf.div(sums, totals, name = "newcents")
#compute the distance the centroids have moved sense the last iteration
dist = centroids-oldcents
sqdist = tf.reduce_mean(dist*dist, name="accuracy")
print np.sqrt(sqdist.eval())
kPoints = centroids.eval()
However, this version is still very inefficient. Notice that we construct a new execution graph for each iteration. A better solution is to pull the graph construction out of the loop and construct it once and reuse it. This is nicely illustrated in Simister’s version of K-means illustrated on his Github site.
It is worth asking how fast Tensor flow is compared with a standard Numpy version of the same algorithm. Unfortunately, I do not have a big machine with fancy GPUs, but I do have a virtual machine in the cloud with 16 processors. I wrote a version using Numpy and executed them both from an IPython notebook. The speed-up results are in Figure 2. Comparing these we see that simple Python Numpy is faster than TensorFlow for values of N less than about 20,000. But for very large N we see that TensorFlow can make excellent use of the extra cores available and exploits the parallelism in the tensor operators very well.
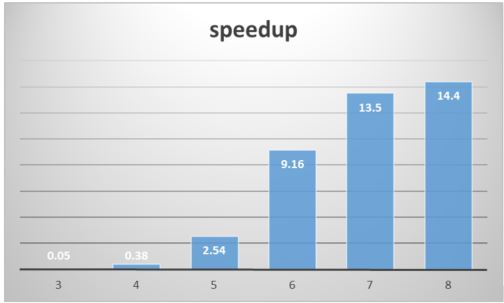
Figure 2. speed-up of TensorFlow on 16 cores over a simple Numpy implementation. The axis is log10(N)
I have placed the source for this notebook in Github. Also an improved version based on Simister’s formulation can be found there.
TensorFlow also has a very interesting web tool call TensorBoard that lets you look at various aspects of the logs of your execution. One of the more interesting TensorBoard displays is the dataflow graph for your computation. Figure 3 below shows the display generated for the k-means computational graph.
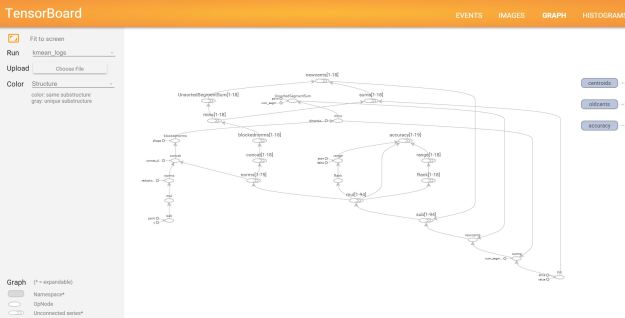
Figure 3. TensorBoard graph displace of the k-means algorithm.
As previously mentioned this is far more complex than my diagram in Figure 1. Without magnification this is almost impossible to read. Figure 4 contains a close-up of the top of the graph where the variable newcents is created. Because this is an iteration the dataflow actually contains multiple instances and by clicking on the bubble for the variable it will show you details as shown in the close-up.
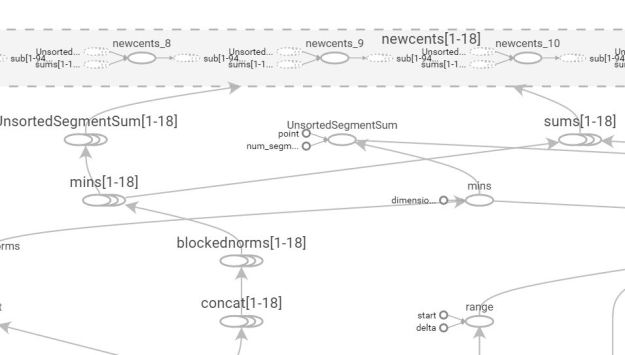
Figure 4. A close-up of part of the graph showing expanded view of the multiple instances of the computation of the variable newcents.
A brief look at a neural network example
The k-means example above is really just an exercise in tensor gymnastics. TensorFlow is really about building and training neural networks. The TensorFlow documents have a number of great example, but to give you the basic idea I’ll give you a brief look at their convolutional deep net for the MNIST handwritten digit example. I’ll try to keep this short because I will not be adding much new here. The example is the well-known “hello world” world of machine learning image recognition. The setup is as follows. You have thousands of 28 by 28 black and white images of hand written digits and the job of the system you build is to identify each. The TensorFlow example uses a two-layer convolutional neural net followed by a large, densely connected layer and a readout layer.
If you are not familiar with convolutional neural nets, here is the basic idea. Images are strings of bits but they also have a lot of local 2d structure such as edges or holes or other patterns. What we are going to do is look at 5×5 windows to try to “find” these patterns. To do this we will train the system to build a 5×5 template W array (and a scalar offset b) that will reduce each 5×5 window to a point in a new array conv by the formula
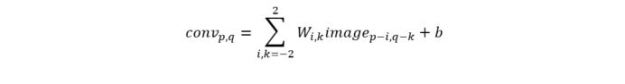
(the image is padded near the boundary points in the formula above so none of the indices are out of bounds)
We next modify the conv array by applying the “ReLU” function max(0,x) to each x in the conv array so it has no negative values. The final step is to do “max pooling”. This step simply computes the maximum value in a 2×2 block and assigns it to a smaller 14×14 array. The most interesting part of the convolutional network is the fact that we do not use one 5×5 template but 32 of them in parallel producing 32 14×14 result “images” as illustrated in Figure 5 below.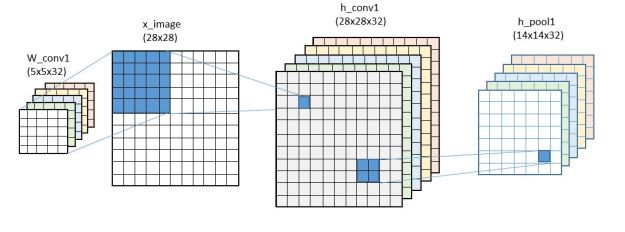
Figure 5. The first layer convolutional network.
When the network is fully trained each of the 32 5×5 templates in W is somehow different and each selects for a different set of features in the original image. One can think of the resulting stack of 32 14×14 arrays (called h_pool1) as a type of transform of the original image much as a Fourier transform can separate a signal in space and time and transform it into frequency space. This is not what is going on here but I find the analogy helpful.
We next apply a second convolutional layer to the h_pool1 tensor but this time we apply 64 sets of 5×5 filters to each the 32 h_pool1 layers (and adding up the results) to give us 64 new 14×14 arrays which we reduce with max pooling to 64 7×7 arrays called h_pool2.
Rather than provide the whole code, which is in the TensorFlow tutorial, I will skip the training step and show you how you can load the variables from a previous training session and use them to make predictions from the test set. . (The code below is modified versions of the Google code found at GitHub and subject to their Apache copyright License.)
Let’s start by creating some placeholders and variables. We start with a few functions to initialize weights. Next we create a placeholder for our image variable x which is assumed to be a list of 28×28=784 floating point vectors. As described above, we don’t know how long this list is in advance. We also define all the weights and biases described above.
def weight_variable(shape, names): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial, name=names) def bias_variable(shape, names): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial, name=names) x = tf.placeholder(tf.float32, [None, 784], name="x") sess = tf.InteractiveSession() W_conv1 = weight_variable([5, 5, 1, 32], "wconv") b_conv1 = bias_variable([32], "bconv") W_conv2 = weight_variable([5, 5, 32, 64], "wconv2") b_conv2 = bias_variable([64], "bconv2") W_fc1 = weight_variable([7 * 7 * 64, 1024], "wfc1") b_fc1 = bias_variable([1024], "bfcl") W_fc2 = weight_variable([1024, 10], "wfc2") b_fc2 = bias_variable([10], "bfc2")
Next we will do the initialization by loading all the weight and bias variable that were saved in the training step. We have saved these values using TensorFlow’s save state method previously in a temp file.
saver = tf.train.Saver() init =tf.initialize_all_variables() sess.run(init) saver.restore(sess, "/tmp/model.ckpt")
We can now construct our deep neural network with a few lines of code. We start with two functions to give us a bit of shorthand to define the 2D convolution and max_pooling operators. We first reshape the image vectors into the image array shape that is needed. The construction of the flow graph is now straight forward. The final result is the tensor we have called y_conv.
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
#first convolutional layer
x_image = tf.reshape(x, [-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
#second convolutional layer
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#final layer
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
y_conv=tf.nn.softmax(tf.matmul(h_fc1, W_fc2) + b_fc2)
Notice that we have not evaluated the flow graph even though we have the values for all of the weight and bias variables already loaded. We need a value for our placeholder x. Suppose tim is an image from the test set. To see if our trained network can recognize it all we need to do is supply it to the network and evaluate. To supply the value to the network we use the eval() function with a special “feed_dict” dictionary argument. This just lists the name of the placeholder and the value you wish to give it.
tim.shape = ((1,28*28))
y = y_conv.eval(feed_dict={x: tim})
label = np.argmax(y)
print(label)
You can read the TensorFlow tutorial to learn about the network training step. They use a special function that does the stochastic backpropagation that makes it all look very simple.
How does this thing work?
Developing an intuition for how the convolutional neural network actually works is a real challenge. The fact that it works at all is amazing. The convolutional steps provide averaging to help create a bit of location and scale invariance, but there is more going on here. Note that given a 28*28 image the output of the second convolutional step is 64 7×7 array that represent feature activations generated by the weight templates. It is tempting to look at these as images to see if one can detect anything. Obviously the last fully connected layer can do a great job with these. But it is easy to see what they look like. If we apply h_pool2.eval(feed_dict={x: image}) we can look at the result as a set of 64 images. Figure 6 does just that. I picked two random 9 images, two 0s, two 7s and three 6s. Each column in the figure represents depicts the first 9 of the 64 images generated by each. If you stare at this long enough you can see some patterns there. (Such as the diagonals in the 7s and the cup shape of the 4s.) But very little else. On the other hand, taken together each (complete) column is a sufficient enough signature for the last layer of the network to identify the figure with over 99% accuracy. That is impressive.

Figure 6. Images of h_pool2 given various images of handwritten digits.
I have put the code to generate these images on Github along with the code to train the network and save the learned weights. In both cases these are ipython notebooks.
A much better way to represent the data learned in the convolutional networks is to “de-convolve” the images back to the pixel layers. In Visualizing and Understanding Convolutional Networks by Matthew Zeiler and Rob Fergus do this and the results are fascinating.
Final Notes
I intended this note to be a gentle introduction to the programming style of TensorFlow and not an introduction to deep neural networks, but I confess I got carried away towards the end. I will follow up this post with another that look at recurrent networks and text processing provided I can think of something original to say that is not already in their tutorial.
I should also note that the construction of the deep network is, in some ways, similar to Theano, the other great Python package for building deep networks. I have not looked at how Theano scales or how well it can be used for tasks beyond deep neural networks, so don’t take this blog as an endorsement of TensorFlow over Theano or Torch.
On a final note I must say that there is another interesting approach to image recognition problem. Antonio Criminisi has led a team that has developed Deep Neural Decision Forests that combine ideas from decision forests and CNNs.
[1] This was before the explosion of massively parallel systems based on microprocessors changed the high-end computing world.
[2] If you are new to neural networks and deep learning, you may want to look at Michael Nielsen’s excellent new on-line book. There are many books that introduce deep neural networks, but Nielsen’s mathematical treatment is very clear and approachable.
[3] This is not a picture of the actual graph that is generated. We will use another tool to visualize that later in this note.
[4] The observant reader will note that we have a possible divide by zero here if one of the special points is a serious outlier. As I said, this is a bare-bones implementation.
