

Abstract.
In 2018 I published a blog about building a cloud-resident “Research Assistant” (RA) chatbot that would be the companion of each scientist. The RA would be responsible for managing scientific data, notes and publication drafts. It could create intelligent summaries and search for important related scientific articles. That post demonstrated a simple prototype that provided spoken English input and simple dialog responses to search for available, relevant research. But it did not address the important issues of data management and textual analysis required to make the RA real. In a short, invited “vision talk” I gave at the e-Science 2019 conference I tried to address the technology that, in 2030, we would need to solve these problems. This article does not describe an implementation. Rather it is a survey of the missing pieces I alluded to in the talk in terms of the current, related literature.
Introduction
2017 was the year of the smart on-line bot and smart speaker. These are cloud based services that used natural language interfaces for both input and output to query knowledge graphs and search the web. The smart speakers, equipped with microphones listen for trigger phrases like “Hello Siri” or “hello Google” or “Alexa” and recorded a query in English, extracted the intent and replied within a second. They could deliver weather reports, do web searches, keep your shopping list and keep track of your online shopping. The impact of this bot technology will hit scientific research when the AI software improves to the point that every scientist, graduate student and corporate executive has a personal cloud-based research assistant. Raj Reddy calls these Cognition Amplifiers and Guardian Angels. We call it a research assistant.
Resembling a smart speaker or desktop/phone app, the research assistant is responsible for the following tasks:
- Cataloging research data, papers and articles associated with its owner’s projects.
- The assistant will monitor the research literature looking for papers exploring the same concepts seen in the owner’s work.
- Automatically sifting through open source archives like GitHub that may be of potential use in current projects.
- Understanding the mathematical analysis in the notes generated by the scientist and using that understanding to check proofs and automatically propose simulators and experiment designs capable of testing hypotheses implied by the research.
Understanding the implications of these 4 properties will be the central theme of this post.
In 2017 we published a short article about how we could build a chatbot for research. In that paper we presented a short overview of chatbot software circa 2017 and demonstrated a very simple toy example meta-search engine that used spoken commands about research interests and the bot would respond with matching documents from Bing, Wikipedia and ArXiv. To illustrate this, consider the sentence “Research papers by Michael Eichmair about the gannon-lee singularity are of interest.” This required out Bot, called the Research Assistant, to understand that the main topic of the sentence was the gannon-lee singularity (an obscure reference to a paper from the 1970s that I happen to know about) and the fact that we want related papers by Michael Eichmair. The result obtained by our Bot shown in Figure 1.
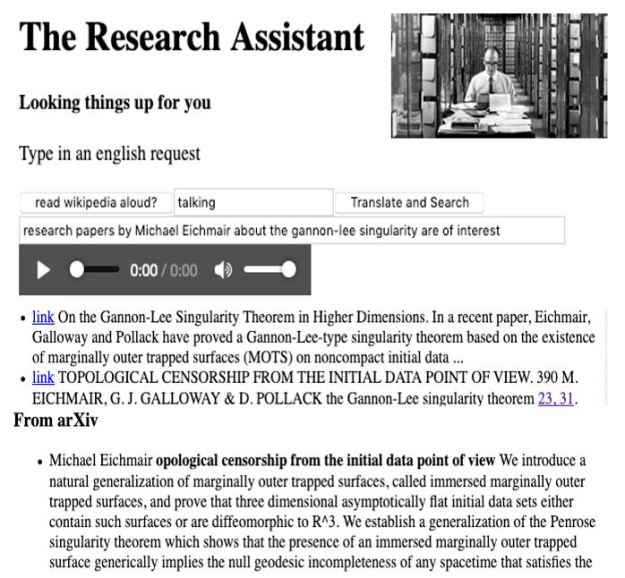
Figure 1. The results (shortened) from our original 2017 Science Bot to the Eichmair question.
In 2019 the same results can now be obtained by directly inserting this sentence into Google or Bing. We suspect one reason for this is the use of vastly improved language models based on Transformers (that we will briefly describe below). Our bot is not only obsolete, we will argue in this article that it completely misses the boat on what is needed to make something truly useful. This report will not present any new research results. Instead it will try to outline the types of tasks required to make the research assistant capable of demonstrating the capabilities listed above. We will try to also give a survey of the best published work leading in these directions. (This report is an expansion of a paper that was originally written for an invited “vision” talk entitled “eScience 2050: a look Back” for the eScience 2019 conference held in San Diego, Sept. 2019.)
Knowledge Graphs
If we look at the first two items in the RA capabilities list above, we see that they go well beyond simple meta search. These tasks imply that the research assistant will need to keep an organized research archive of data, notes and papers and have the ability to extract knowledge from the literature. We will assume that the individual items the RA manages will be cloud-resident objects that are described by a searchable, heterogeneous database of metadata. One such database structure that can be used for this purpose is a Knowledge Graph (KG). KGs are graphs where the nodes are entities and the links between nodes are relations. Often these node-edge-node triples are represented using Resource Description Framework (RDF) which consist of a subject, a relationship and an object. Each element of the triple has a unique identifier. The triple also has an identifier so that it can also be subjects or objects.
Having a KG that is based on scientific ontological terms and facts that can be augmented with the content of the individual scientist would be the proper foundation for our RA. To help explain this we need to take a diversion into the existing triple store KGs to see if there is one we can build upon.
There are several dozen implementations of RDF triple stores and many are open source. In addition, there are a number of commercial products available including
- Ontotext which produces GraphDB a commercial RDF knowledge graph used by commercial custormers in publishing ( BBC and Elsevier), pharmaceuticals (AstraZeneca) and libraries (Mellon funded projects for the British Museum and the US National Galery of Art)
- Grakn Labs in the UK had a knowledge graph Grakn that has special versions such as BioGrakn for life science apps.
- Cambridge Semantics has a product called AnzoGrapDB which has numerous customers in the pharmaceutical domain.
- And, of course, Oracle has a version of its database called “Spatial and Graph” that supports very large triple stores.
If you search for Knowledge Graph on the web or in Wikipedia you will lean that the KG is the one introduced by Google in 2012 and it is simply known as “Knowledge Graph”. In fact, it is very large (over 70 billion nodes) and is consulted in a large fraction of searches. Having the KG available means that a search can quickly surface many related items by looking at nearby nodes linked to the target of the search. This is illustrated in Figure 2 for the result of a search for “differential equation” which is displayed an information panel to the right of the search results.

Figure 2. Google information panel that appears on the right side of the page. In this case the search was for “differential equation”. (This image is shortened as indicated by …).
Google’s Knowledge Graph is not as good for science topics as the example in Figure 2 suggests. In fact, it is extremely good with pop culture, but for science applications like our RA, Google’s KG often just takes information from Wikipedia. In its earliest form Google KG was based on another KG known as Freebase. In 2014 Google began the process of shutting down Freebase and moving content to a KG associated Wikipedia called Wikidata. However, the Freebase archive is still on-line had has some excellent science content.
Launched in 2012 with a grant from Allen Institute, Google and the Gordon and Betty Moore Foundation Wikidata information is used in 58.4% of all English Wikipedia articles. Items in Wikidata each have an identifier (the letter Q and a number) and each item has a brief description and a list of alias names. (For example, the item for Earth (Q2) has alternative names: Blue Planet, Terra Mater, Terra, Planet Earth, Tellus, Sol III, Gaia, The world, Globe, The Blue Gem, and more.) each item has a list of affiliated “statements” which are the “object-relation-object” triples that are the heart of the KG. Relations are predicates and are identified with a P and a number. For example, Earth is an “instance of” (P32) “inner planet” (Q3504248). Figure 3 shows an illustration of the item “Hubble Telescope”. There are currently 68 million items in Wikidata and, like Wikipedia it can be edited by anyone.
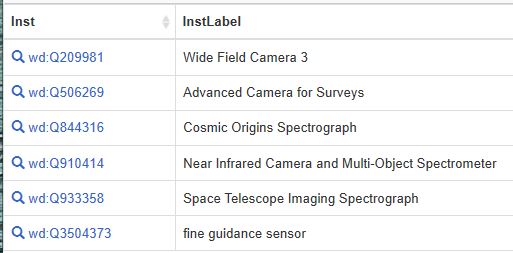
Having a KG is not very useful unless you have a way to search it. In the case of Wikidata (and other RDF KGs) the language for making queries is called SPARQL. Combined with Wikidata, SPARQL queries are a very powerful way to search the KG. To give a trivial example of what a SPARQL query look like let’s search for all the scientific instruments carried on the Hubble Telescope.

Figure 3. Wikidata object Q2513, Hubble Telescope. This is an edited version of the full entry which has dozens of property statements.
To write the query we need to know that Hubble had id wd:q2513 and that the predicate “carries scientific instrument” is wdt:P1202. The query and results are shown below. To read the query note there are two unbound variables ?Inst and ?InstLabel. The only significant part of the request is a match for tuples of the form (Hubble telescope, carries scientific instrument, ?Inst).
SELECT ?Inst ?InstLabel WHERE {
SERVICE wikibase:label { bd:serviceParam wikibase:language “[AUTO_LANGUAGE],en”. }wd:Q2513 wdt:P1202 ?Inst.
} LIMIT 100
The table below shows the output.
This example does not do justice to the power of the search capabilities. A look at the example in the Wikidata Query Service will illustrate that point.
One of the more impressive KGs for science is the Springer Nature SciGraph which has over 2 billion triples related to scientific topics. While the content contains the full Springer content, it goes well beyond that such patents and grant awards. Zhang et.al [zhang] have demonstrated the use of knowledge graphs for recommendations in the NASA Science Knowledge Graph (SKG) .
Building specialized KGs for science domains has been going on for a while. In 2009, the Hanalyzer (short for high-throughput analyzer) system uses natural language processing to automatically extract a semantic network from all PubMed papers relevant to a specific scientist.
Where’s the Data?
This brings us to the question is Wikidata a place to store experimental data sets? The usual approach to data set description is via Schema.org. However recent work by one of the Wikidata founders, Denny Vrandecic, and presented at the workshop Advanced Knowledge Technologies for Science in a FAIR World (AKTS) entitled Describing datasets in Wikidata described how this can be done when schema.org may not be sufficient. At that same workshop Daniel Garijo, Pedro Szekely described a way the extended Wikidata to support external collection in a presentation entitled WDPlus: Leveraging Wikidata to Link and Extend Tabular Data. We shall ague below that this is an important possible component of the research assistant.
The Semantic Scholar Literature Graph
There is a very different approach to the problem of storing information about research papers than Wikidata. The Allen Institute for Artificial Intelligence (AI2) has built the Semantic Scholar, a graph of the scientific literatures that has a structure that is tightly focused on research paper, their authors and the concepts in the papers that link them together. More specifically, the Semantic Scholar Literature Graph, as described by Waleed Ammar, et. al has the following node types:
- Author – a person record
- Paper – a paper has a title, venue, year, etc.
- Entities – unique scientific concepts like “deep learning” or “natural language processing”.
- Mentions – references to entities from text
The nodes are linked by edges including author-to-paper, paper-citations, and mentions which are references in the text to entities. Between mentions, edges link mention in the same sentence and between entities that are somehow related. Figure 4 illustrates the graph.
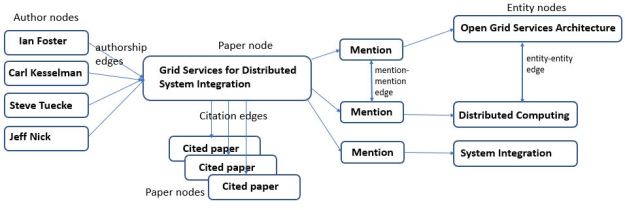
Figure 4. An approximate subgraph of the Literature Graph for a paper in Semantic Scholar.
Many of the entity node are associated with items in Wikimedia.
Another related project from AI2 is the GraphAL [GraphAL] query system for the knowledge graph. The query system can be accessed on-line. The types of queries that can be expressed are powerful. For example, finding the papers that mention certain pairs of entities, or all authors of papers that mention a certain entity. We shall return to this capability below.
Building the Research Assistant
If we consider the first of two tasks on our requirements list for the RAs functionality
- Cataloging research data, papers and articles associated with its owner’s projects
we see that this challenge may be well met by having the RA possess a copy of Wikidata together with the extensions described by Denny Vrandecic discussed above. If not that then Garijo and Szekely’s WDPlus Wikidata extension may be a perfect solution.
Turning now to the second task:
- The assistant will monitor the research literature looking for papers exploring the same concepts seen in the owner’s work
we see the nature of the challenge is very different, but progress has been made on this task. Xiaoyi et.al have shown it is possible to use a combination of neural networks and rule-based reasoning to identify semantic entities and even implicitly cited datasets in earth science papers.
Given a set of research notes, grant proposal or draft of research papers, we need a way the way to identify the concepts in the user’s documents and then insert them into a version of the Semantic Scholar Literature graph. To do we can use a language model to scan the documents looking for interesting literature terms. The state of the art for language parsing has made great strides over the last few years and we will look at one called Bidirectional Encoder Representation from Transformers (called BERT)
Using BERT to extract knowledge from documents
Most older language analysis models were built from deep LSTM networks (which we discussed in our book on cloud computing). These models were unidirectional in that the processed text from right to left or left to right in order to train the network. Devlin et.al published the BERT paper in 2018 and revised it in 2019. BERT is unique in several respects. First it is designed so that it can be “pre-trained” on plane text to build a special encoder. Then, for various language analysis tasks, such as question answering, paraphrasing and language inference, an additional layer is added so that the encoder plus the new layer can be tuned to address the task. (This is a type of transfer learning we have described before.) What makes this possible is the way BERT uses an encoder that captures a whole sentence at a time. The training is done by masking out a small number of words (15%) in the input and then using a loss function that measures how well the network predicts the correct masked word. Figure 5 below illustrates this. The core of the encoder is based on transformers which have been shown to be powerful ways to capture context. (See the harvardNLP Annotated Transformer for a detailed walk through of building transformers.
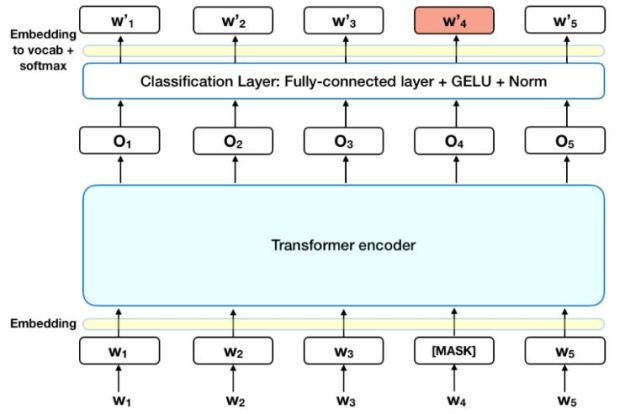 Figure 5. Bert training of the encoder based on masking random words for the loss function. This figure taken from “BERT – State of the Art Language Model for NLP” by Rani Horev in Lyrn.
Figure 5. Bert training of the encoder based on masking random words for the loss function. This figure taken from “BERT – State of the Art Language Model for NLP” by Rani Horev in Lyrn.
Another good blog explaining BERT and the transformers is by Ranko Mosic. The AllenNLP group has an excellent demo using the masked language model and this is illustrated in Figure 6. This shows the result of using a sentence “Multicore processors allow multiple threads of execution to run in parallel on the various cores.” with processors, execution and parallel masked. You can note that it did a rather good job (code is a reasonable substitute for execution here.)

Figure 6. The AI2 masked language model demo using the sentence “Multicore processors allow multiple threads of execution to run in parallel on the various cores.” with processors, execution and parallel masked.
Another application of a BERT based language model is semantic role labeling. This is good for analyzing sentences and identifying a subject verb and object. For our purposes this is important. We would like to extract from the scientists document key scientific terms and the implied relations between them. With this we can query the literature graph for matches, or we can use it to extend the scientist private version of the literature graph or knowledge graph.
For example, a researcher working on papers related to programming of parallel computers may have key phrases that include, multicore programming, data parallel, multithreaded programs, synchronization, map reduce, BSP, etc. The type of triples we may discover by mining the documents may include
(map reduce, used in, data parallel programming)
(multicore processors, speedup, multithreaded execution)
(synchronization problems, encountered in, multithreaded programs)
(locking mechanisms, solve, synchronization problems)
(bulk synchronous parallel, solve, synchronization problems)
(BSP, alias, bulk synchronous parallel)
(map reduce, type of, parallel algorithm)
The first and third elements of the triples correspond to entities that are associated with mentions in the document. The verbs are potential labels for entity-entity edges in the graph.
To demonstrate the capability the AI2 implementation of sematic role labeling we downloaded the language model and used it in a Jupyter notebook. We tested it with a sentence related to general relativity:
A gravitational singularity is a place where gravity has caused an event horizon which created a black hole in space, but a naked singularity is a gravitational singularity that does not have an event horizon and, therefore naked singularities do not create a black hole.
Running this through the “predictor” function of the bert-base-srl-2019.06.17 model gives the output in Figure 7.
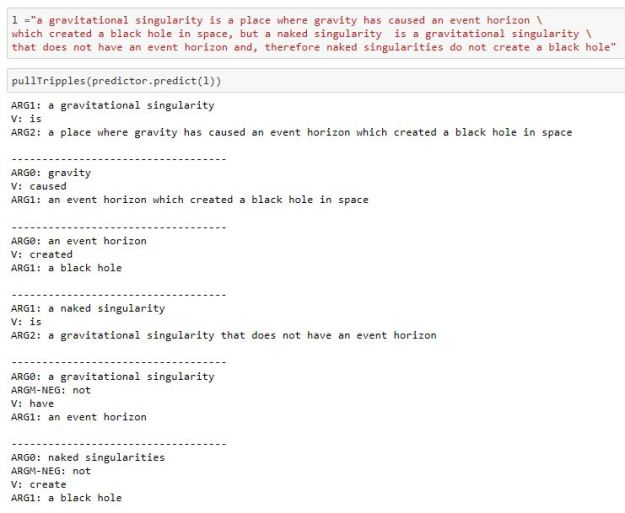
Figure 7. Output of “predictor” function of the bert-base-srl-2019.06.17 AI2 model. The code to download the model for python is given in the document associated with the demo. The function pullTripples is a post processor which removes annotations not essential for this illustration and formats the output.
As can be seen in the figure the model identified the key noun phrases (naked singularity, gravitational singularity, event horizon, black hole and gravity) as well as a sequence of reasonable triples. It should be possible to use the GraphAL query system to find associated entities on the literature graph. Indeed, a simple search in Semantic scholar for these terms will find dozens of related papers. From these results, one can build a personal literature graph for each of the owner’s documents with links to the discovered material.
The Really Hard Problems
The final two requirements for the research assistant pose some really hard problems.
- Automatically sifting through open source archives like GitHub that may be of potential use in current projects.
- Understanding the mathematical analysis in the notes generated by the scientist and using that understanding to check proofs and automatically propose simulators and experiment designs capable of testing hypotheses implied by the research.
Github already has a very good search interface that can be used to discover resources related to specific general topics. For example, searching for “multicore programming” retrieves an excellent collection of archives that address the relevant to topics of parallelism and synchronization.
The Github machine learning group (yes, every organization these days has a ML or AI group) has done some nice work on using LSTM networks to translate English language text such as “ Read csv file into Pandas dataframe”, into the corresponding Python code. This is done by building a good vector space embedding of the English statement and a trained LSTM that creates English summaries of code fragments. By associating the summaries with the original English question, they can map the question to the associated code. The Github team is also collaborating with Microsoft Research Cambridge where a team is working on Program Understanding. While all of this is still very early work it appears to be very promising.
Automatically “understanding” mathematical analysis
The fourth property in our RA list reaches way beyond current capabilities. The work from the GitHub team described above can make translating English program requirements into code very similar to natural language translation, but anything involving “understanding” is, for now, out of reach. However, there have been some interesting early attempts to bridge language and models of scientific theory. Eureka (now DataRobot) does automatic AI based time series analysis and DataRobot is also a tool for automatically building ML models given only data. Michael Schmidt and Hod Lipson consider the problem of deriving theoretical mathematical models directly from experimental data (see Figure 8).
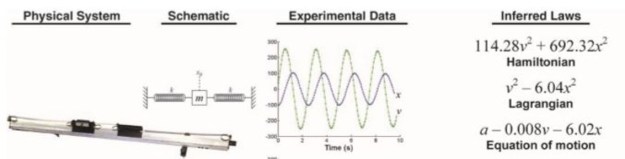
Figure 8. From Michael Schmidt and Hod Lipson, Distilling Free-Form Natural Laws from Experimental Data. (SCIENCE VOL 324 3 APRIL 2009)
Automatic theorem checking research has been going on for years, but these systems require formal statements of the theorem to be checked and are usually designed for human-machine collaboration. If it were possible to create a system that could take a journal paper and automatically extract a formal expression of the mathematical content in a form that a checker could input, then we would be getting close to the goal.
The most impressive work on using the advanced deep learning technology to “comprehend” scientific text comes again from the AI2 team. Their system Aristo is “an intelligent system that reads, learns, and reasons about science”. Aristo recently got an “A” on the N.Y. Regents 8th grade science exams. This exam consists of multiple-choice questions such as the following:
Which object in our solar system reflect light and is a satellite that orbits around one planet? (A) Moon, (B) Earth, (C) Mercury, (D) Sun.
Aristo works by combining a number of component solvers to bear on the problem. Information retrieval and statistics for am important layer. Pointwise mutual information is used to measure the likely hood of each Question-Answer pair against information retrieved from the text corpus. A quantitative reasoning solver is used to address questions that involved basic quantitative statements. As shown in Figure 9, a tuple inference solver builds graphs that connect tuples from a scientific knowledge base to the terms in the question and the answers. Dalvi, Tandon and Clark have constructed an excellent knowledge base of science-related triples called the Aristo Tuple KB/.
The graphs with the most promising connection to one of the answers is the winner.
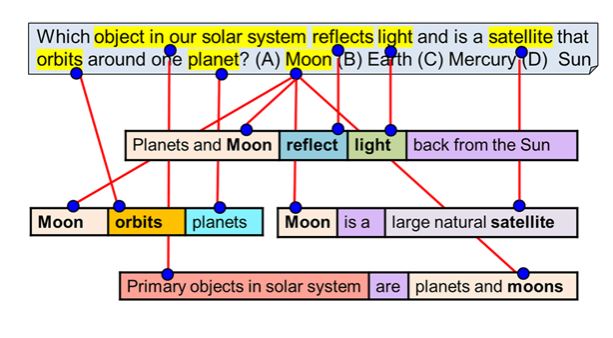
Figure 9. From Clark, et.al, From ‘F’ to ‘A’ on the N.Y. Regents Science Exams: An Overview of the Aristo Project. https://allenai.org/content/docs/Aristo_Milestone.pdf Aristo Tuple Inference Solver. Key terms in the question and answer candidates are linked to triples from the knowledge base.
While the Aristo work is a real milestone, it has far to go. In particular, it does not yet have the ability to relate technical diagrams and equations in the text into its deductive (or abductive) analysis. I expect AI2 is working on this now. The bigger challenge, being able to classify documents by the content of the mathematical arguments used, is very hard when reasoning is spread over many pages. There is some interesting automatic document summarization work, but it is not up to this challenge.
Final Thoughts
This discussion is far too incomplete to warrant a “conclusions” section. The ability of the research assistant to take and idea and run with it is central to what we need. The idea may be a theory expressed in a draft technical paper or research proposal. Finding all the related publication is certainly a start, but first the RA must be able to abstract the important original ideas and not just the keywords and phrases. It may be that the key idea is a more of a metaphor for a larger truth that manifests itself in research in various disciplines. But this is probably more than any RA can grasp.
There is going to be amazing progress over the next 30 years. This is obvious when one looks at the state of computing 30 years ago. Much of what we have today was then only a dream.
This post contains a look at many active research projects, and I am sure I am missing some very important ones. Please contact me if I have mischaracterized any of them or if I have missed something really important.
References
Most of the citations to literature in this blog are linked in-line. Here are two for which I found it easier to provide explicit reference.
[grapAL] Christine Betts, Joanna Power, Waleed Ammar, GrapAL: Connecting the Dots in Scientific Literature, arXiv:1902.05170v2 [cs.DB] 19 May 2019
[zhang] Jia Zhang, Maryam Pourreza, Rahul Ramachandran, Tsengdar J. Lee, Patrick Gatlin, Manil Maskey, and Amanda Marie Weigel, “Facilitating Data-Centric Recommendation in Knowledge Graph”, in Proceedings of The 4th IEEE International Conference on Collaboration and Internet
Computing (CIC), Philadelphia, PA, USA, Oct. 18-20, 2018, pp. 207-216.
