
(This is an edited version correcting some of the analysis in the version i posted last week)
Microservice architectures have become an important tool for large scale cloud application deployment. I wanted to understand how well a swarm of microservices could be used to process streams of events where a non-trivial computation is required for each. I decided a fun test would be to use machine learning to classify scientific document abstract that appear on public RSS feeds. This is the first result of that experiment. It uses a very small Mesosphere cluster on Microsoft Azure. I will release the code to GitHub and data as soon as i clean it up a bit.
In a previous post we looked at building a document classifier for scientific paper abstracts. In this post we will see how we can deploy it as a network of containerized microservices running on Mesosphere on Microsoft Azure. We will then push this network of services hard to see how well it scales and we will try to isolate the performance issues. Specifically we are interested in the following challenge. If you have a heavy stream of events coming into a stream analysis system you may overload your services. The conventional wisdom is that you can scale up the number of servers and services to cope with the load. Fortunately more than one microservice instance can be deployed on a single VM. But does increasing the number of services instances per VM allow us to scale the system to meet the throughput requirements? Are there fundamental limits to how well this strategy will work? What are the limiting factors?
To summarize where we are so far, we have a set of RSS feeds that are “pushing” scientific publication events to us. Our system looks at the abstracts of these events and use several different machine learning tools to classify the document into one (or more) scientific disciplines and sub-disciplines. We have five major disciplines: Physics, Math, Biology, Computer Science and Finance. Each of these major disciplines is further divided into a number of sub-disciplines or specialties. We have divided the work into four main activities
- Training the classifiers. For this we used some of the labeled data from the ArXiv RSS feeds as training data. (This was discussed in detail in the previous post, so we won’t go over it again here.) This training phase is used to generate models that will be used by the classifier services discussed here. We generate models for the main topic classifier and each of the sub-domain classifiers. This is a pre-processing step and it is not counted in our performance analysis.
- Pulling the events from the RSS feeds and pushing them to the main topic classifier. The main topic predictor/classifier uses two primary machine learning methods to determine which disciplines the incoming documents belongs to. As we have seen, these two methods agree on the discipline about 87% of the time. But sometimes they disagree on a document and we have two potential correct answers. We interpret this as a potentially “interdisciplinary” research document and classify it as belong to both answers.
- Doing the sub-domain classification. As shown in the Figure 1 below the major topic classifiers push the document to the one (or two) sub-discipline specific classifiers. These classifiers use the same ML methods as the main topic classifier to further classify the document into the sub-disciplines.
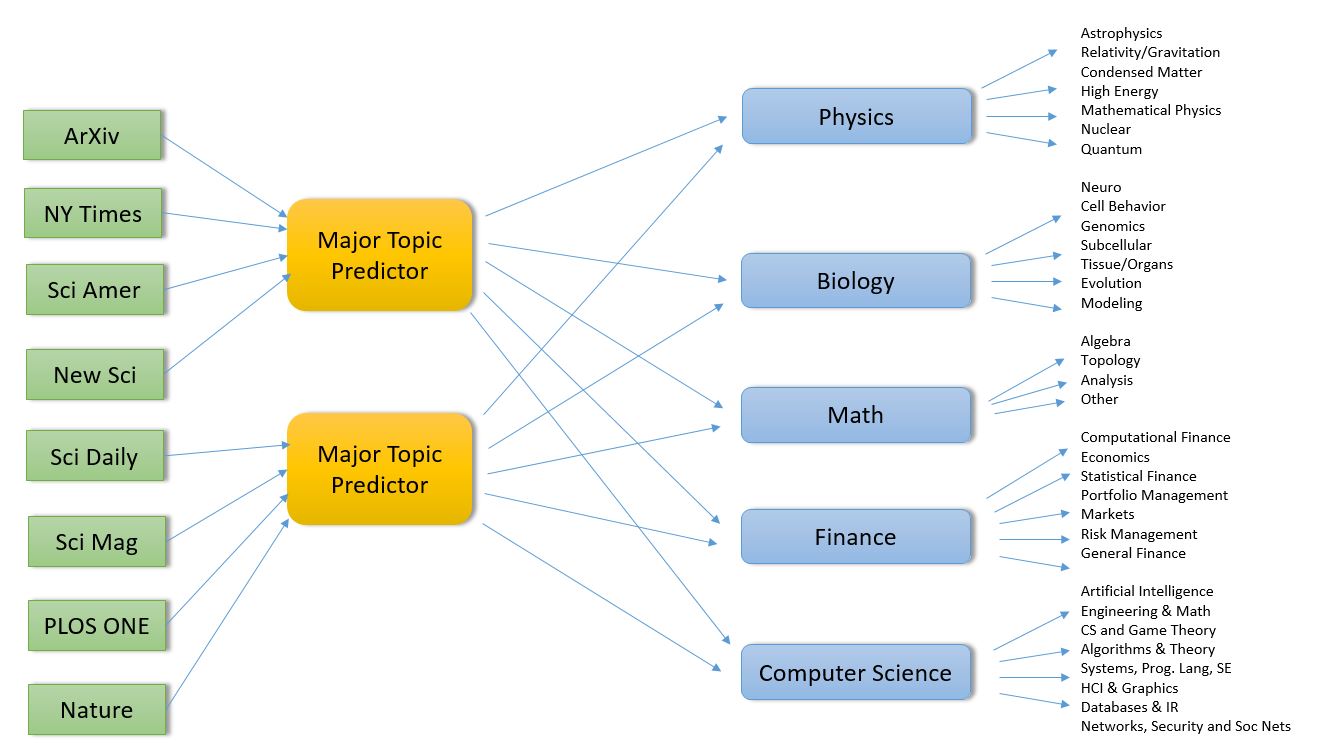
Figure 1. Conceptual model of the document classifier microservice architecture
Managing queues and Pushing the classified document to a table of results.
What is not shown in the diagram in Figure 1 is what happens next. While the conceptual model provides a reasonable top-level view, the real design requires several additional critical components. First as events move through the system you need a way to buffer them in queues. We use the Active Message Queuing Protocol (AMQP) which is one of the standards in this space. A good implementation of AMQP is the RabbitMQ system which we hosted on a server in the Azure cloud. As shown in Figure 2 we (logically) position the RabbitMQ event hub between the major topic classifiers and the sub-domain classifiers. We establish 7 queues on the event hub. There is a queue for each of the major topic areas (Physics, Bio, Math, CS, and Finance), a “status” queue and a “role” queue. The classify microservices are given classification roles by polling the “role” queue. This tells them which topic area they are assigned to. When they complete the sub-domain classification of a document they invoke another microservice that is responsible for storing the result in the appropriate table partition for later lookup by the users. This microservice sends an acknowledgement of the completed classification back to the event “status” queue prior. We shall refer to this microservice as the Table Web Service. The “Status Monitor” is the overall system log and is critical for our performance measurements.
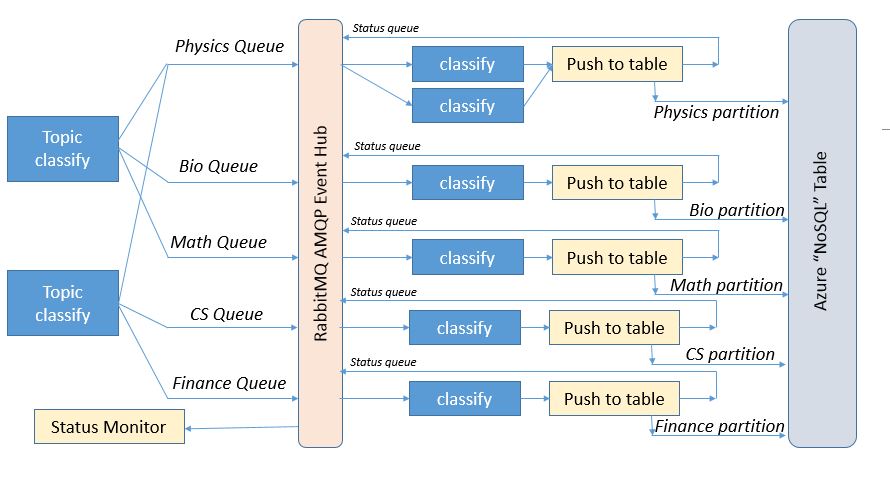
Figure 2. The detailed architecture picture.
The Execution Environment
The RabbitMQ server is hosted on a Linux VM on Microsoft Azure and the rest of the system is deployed on a small Mesosphere cluster in a different Azure data center (see Figure 3). The cluster is indeed small. There is one master node that runs the Mesosphere life cycle management services, the web browser interface and Marathon job management service. There are 5 dual core worker VMs. The Azure table is also a separate service. The experiment status monitor runs in an IPython Notebook on my laptop. 
Figure 3. Execution Environment
Using the web interface for Marathon we deploy different service configurations for the experiments described here. Our table-pusher web service listens on a fixed port, so we can only have one instance per worker VM. In practice this works out reasonably well because the classify services on any VM can invoke the local copy with very little overhead. However, as we shall see, there are other major overheads associated with this service that will play a large role in the performance analysis.
We are not limited by the number of classify services we deploy. If the system operator wants 20 “physics” sub-domain classifiers, the operator need only increase the deployment size of the classifier service by 20 and then submit 20 “physics” role messages into the role queue.
The Microservice Life Cycles
The top-level topic classifiers take the data from the RSS streams and apply the machine learning algorithms to produce the best 1 (or 2) potential topics. The result is converted to a json object which contains
- The domain as determined by the random forest classifier we call RF
- The domain as determined by a hybrid classifier we call “the best of 3 classifier” (see the previous post) we call Best.
- The title of the document
- The body (abstract) of the document.
This doc json object is then pushed into the queue specified by the ML classifiers. If both RF and Best agree on a topic like “math” then the document is put in the “math” queue. If they disagree and one says “math” and the other says “bio” then the document is placed in both the “math” and “bio” queues. The classifier microservice has the following life-cycle.
ML Classifier
- When launched it opens a connection to the “roles” queue and wait for a topic.
- When it receives the topic message from the “role” queue the classifier service, must initialize all the ML models for that topic from the saved trained models. (The models have been previously trained as described in the previous post and the trained models have been “pickled” and saved as blob in Azure blob storage.)
- It then begins to scan the queue for that topic. It pulls the json document objects from the queue and applies the classifier. It then packages up a new json object consisting of the main topic, new sub-classification, title and abstract. For example, if the item came from the “physics” queue and the classifier decides it in the subclass “General Relativity”, then that is the sub-classification that in the object. (The classifier also has a crude confidence estimator. If it is not very certain the sub-classification is “General Relativity?”. If it is very uncertain and General Relativity is the best of the bad choices, then it is “General Relativity???”.) It then sends this object via a web service call to a local web service (described below) that is responsible for putting the object into an Azure table. (more on this step below. )
- The service repeats 3 until it receives a “reset” message in the topic queue. It then returns to the roles queue and step 1.
Table Web Service
(note: this is a revised version. the reliable and fast versions were incorrectly described in the previous version of this post.)
The table web service is the microservice component that receives web service invocations from the classifier. Staying true to the Microservice design concept it has only one job.
- When Invoked it pulls the json object from the invocation payload and formats a Table service tuple to insert into the partition of the table associated with the main topic.
- We actually have three versions of web service one we call “fast” and the other “reliable” and the other is “null”.
- The “reliable” version works by making a new connection to the RabbitMQ event server and then opens a channel to send it messages. It then inserts the tuple in table and then sends a time stamped status notification to the event queue.
- The “fast” version reuses the RabbitMQ connection for as long as possible. For each invocation it opens the channel and inserts the message.
- The “null” version skips the Azure table entirely and is used only for the performance evaluation.
(Unfortunately, the RabbitMQ connection will timeout if there is a lull in the use and catching the timeout connection and restarting it proved to be problematic. So the “fast” version is only used to illustrate the performance models below. It is not reliable. The “reliable” version is very reliable. It runs for months at a time without problems. As we shall see, it is slower. The “null” version is fast and reliable but not actually useful for anything other than benchmarks.)
- Before returning a web service response to the calling classifier instance the web-service sends a time-stamped message to status queue.
The Experiment
It was stated at the outset of this document that we are interested in understanding the effect of scaling the number Docker containers on the ability of the system to meet the flow of events into the system. To test the system under load we pre-loaded 200 abstract for the Biology topic into the message queue and all the classifier service instances were instructed to be Biology sub-topic classifiers. We then ran this with 1, 2, 4, 8, 16 and 24 instances of the classifier microservice. We ran this against all three versions of the table web service. To compute the elapsed time to consume and process all 200 abstracts the table web service appended a timestamp to each status message. By looking at the time stamp for the first message and the last message we could determine the system throughput. (There were five different worker VMs so there is a small issue of clock skew between timestamps, but this was negligible. What was not negligible was delays cause by network traffic between the data centers. Hence I would estimate that the error bars for all the number below to be about 10%. We ran many tests and the number below are averages.
The most important number is the throughput of the system in classifications per second. The table in Figure 4 summarizes the results. Clearly the best throughput was obtained with the combination of the null classifier and the null table service. The next best was the combination of the classifier and the null table service.

Figure 4. Throughput results for 1, 2, 4, 8, 16 and 24 instances of the classifier service.
The combination of the classifier and either the fast or reliable table service showed rather poor performance. To understand this we need to look at the basic flow of execution of a single classifier and a single table web service as shown in Figure 5. Note that the classifier that invokes the web service cannot return to fetch another task until the table web service has sent the status message.

Figure 5. Flow of control of the classify-table web service from the message queue and back.
To understand where congestion may exist look at the points where resource contention may occur when multiple classify instances are running. This is illustrated in Figure 6.
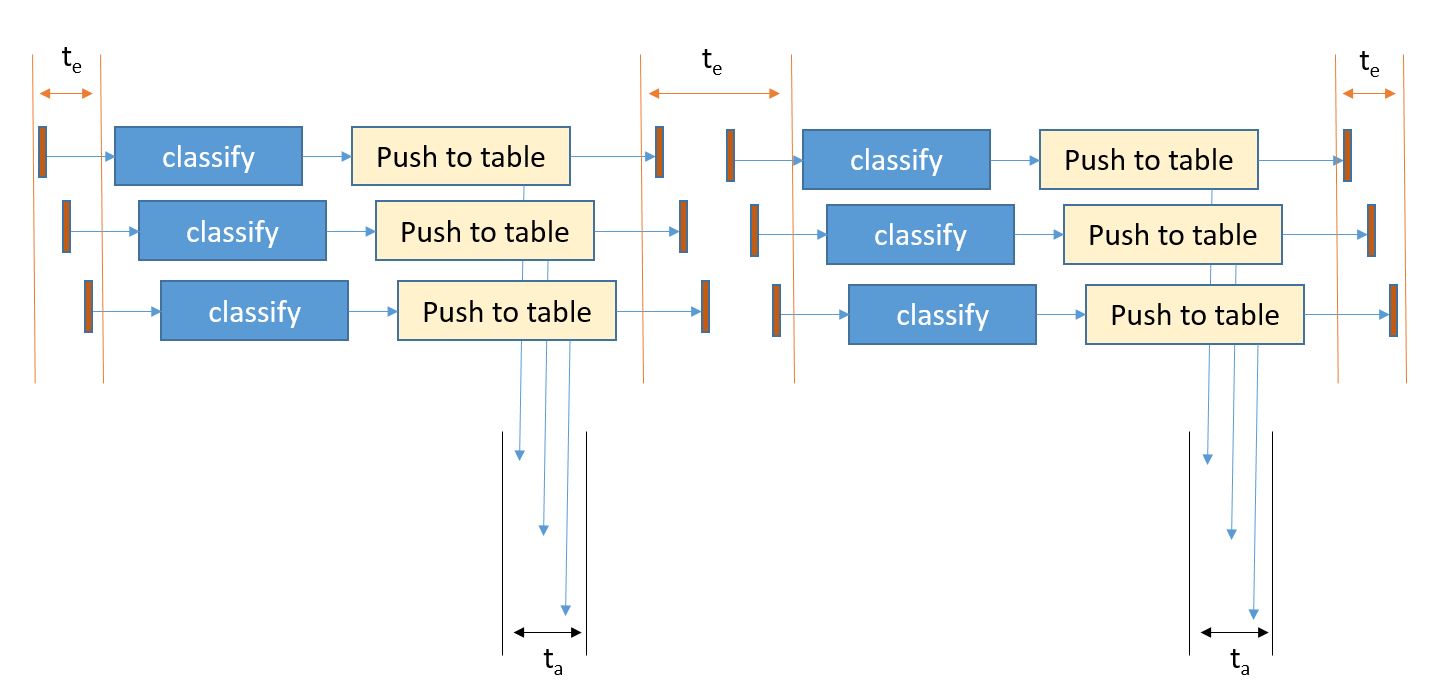
Figure 6. The major points of resource contention occur when the services access the Azure Table service and the RabbitMQ message broker.
Quantifying this let

We can do a very crude speedup analysis based on Amdahl’s law. Looking at the part of the computation that is purely parallel and assuming sequential access to the Table service and message broker we can say
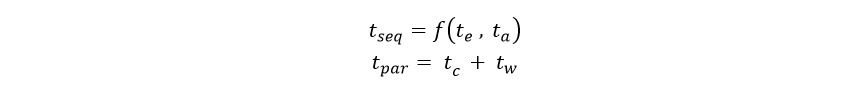
tseq is a function of the two points of contention. It turns out that the message queue is fast in comparison to the Azure table service. This is due to the complexity of inserting an item into a table. Because we are only using one table partition “Biology” all our inserts go into one place. Unfortunately, inserts into any disk-based system are going to involve locks so this is not surprising. However, the difference between the fast version and the reliable version illustrate the high cost of establishing a new connection to the message broker for each event. I am not sure what the function “f” is above but i suspect it is additive.
Let Tserial be the time for one instance of the classify service to complete the execution the set of messages and Tpar (n) be the time it takes n instances to do the job. We then have
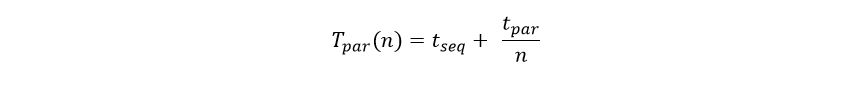
The speedup of n classifiers over a single classifier is then
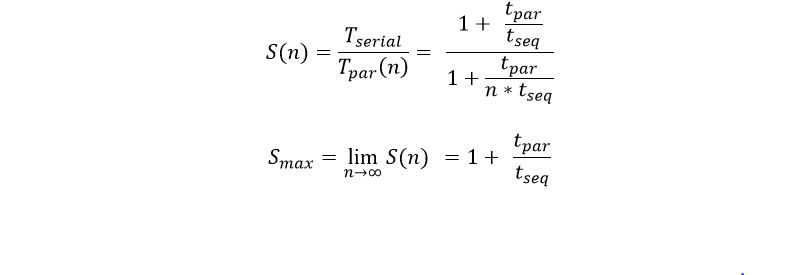
Analysis of the data on the time to do a single classifier with no table service give us tpar = 450 ms (approximately) and tseq = 60 ms for the fast service and 100 ms for the reliable service. Using the formula above we have the maximum speed-up Smax = 8.5 for the fast service an 5.5 for the reliable service. This approximately agrees with the results we can measure as seen in figure 7 below.
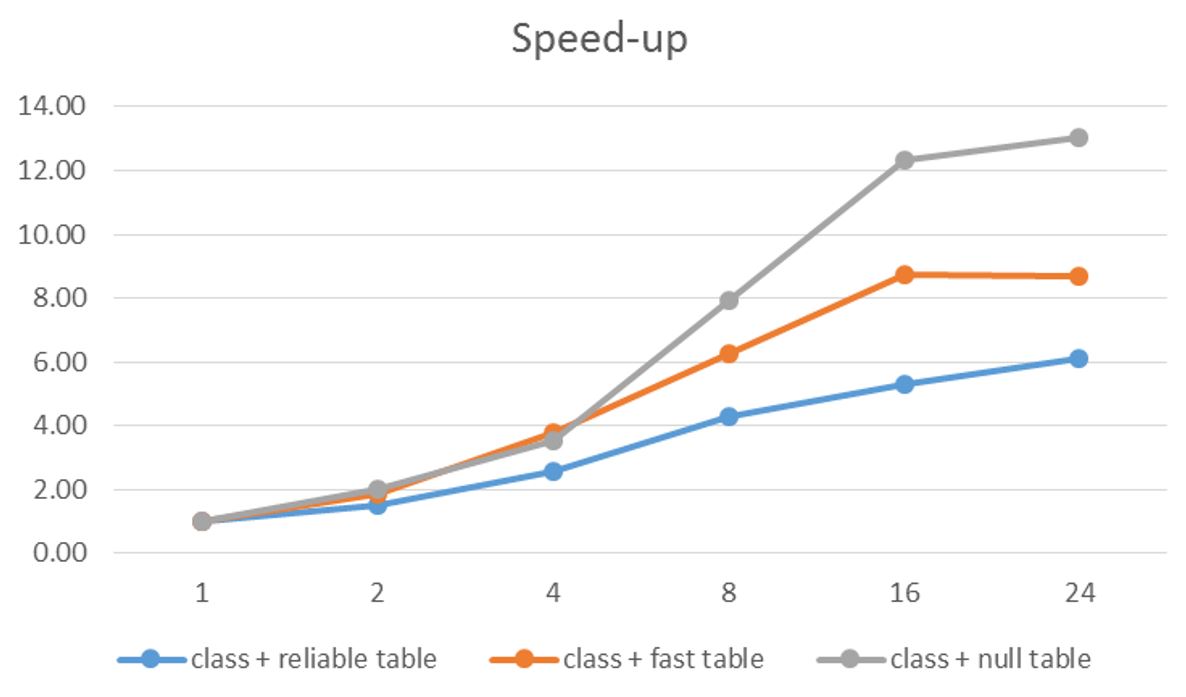
Figure 7. Speed-up relative to one instance of the classifier with different table services plotted against different numbers of classifier instances.
Of course speed-up is a relative number, but it does illustrate the way systems scale. As we can see the limits are approximately what we predicted. However the case of the null table is different. There should be essentially no sequential component so why is it flat-lining at around 13? The answer is that there are only 10 cores in our system. That puts a fundamental limit on the performance. In fact we are lucky to get more than a speed-up of 10.
Conclusions
One thing that does not come out in the text above is how well the concept of microservices worked. One of the major selling points for this style of application construction is that factoring of the services into small independent components can help with maintenance of the overall system. Using Mesosphere and the Marathon task scheduled proved this point well. It was possible to modify, remove and scale any of the services without having to bring down the others. This made all of the experiment described above easy to carry out. And the system remained up for several months.
It is clear that 10 cores is not a very impressive platform to test scalability. We did demonstrate that we could easily scale to about 2.5 services per core without problems. Going beyond that did not improve performance. I am currently trying to build an instance of Mesosphere or other Docker cluster mechanism (perhaps Swarm) with at least 100 servers. I will update these results when i have that complete.
Another thing to do is cache the table writes and then update the table with an entire block. A good solution for this is to introduce a Redis cache service. Fortunately Docker makes this trivial. Redis containers are in the library. Doing this and having a much larger cluster should enable at least a 20x improvement.
Actually, a more interesting experiment is to try this classification problem using one of the more conventional tools that already exist. For example Microsoft Stream Analytics + Azure Machine Learning & Microsoft StreamInsight, Spark Streaming + Event Hubs and HDInsight, Amazon Kinesis, Google BigQuery, IBM Watson Analytics and numerous open source IoT platforms. I plan to start with the Azure solution while i still have Azure resources.
I am in the process of moving all the code and data for this experiment into GitHub. I will post link to these items in the next week or so.
