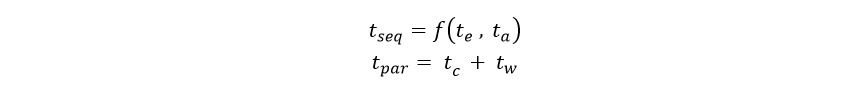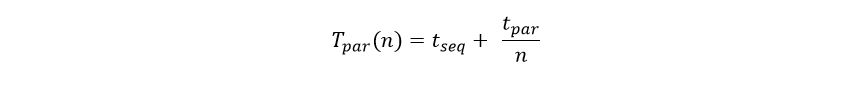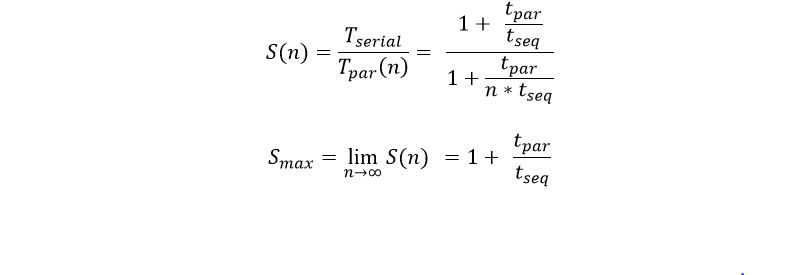
UPDATE! Microsoft has just recently released a much better way to integrate Azure Machine Learning with Azure Stream Analytics. You can now call an AzureML service directly from the SQL query in the stream analytics system. This means you don’t need the message bus and microservice layer I describe below. Check out the blog by Sudhesh Suresh and the excellent tutorial from Jeff Stokes. I will do a performance analysis to compare this method to the one below, but I will wait until the new feature comes out of “preview” mode :). I will also use a better method to push events to the eventhub.
Doing sophisticated data analytics on streaming data has become a really interesting and hot topic. There is a huge explosion of research around this topic and there are a lot of new software tools to support it. Amazon has its new Kinesis system, Google has moved from MapReduce to Cloud DataFlow, IBM has Streaming Analytics on their Bluemix platform and Microsoft has released Azure Stream Analytics. Dozens of other companies that use data streaming analytics to make their business work have contributed to the growing collection of open source of tools. For example LinkedIn has contributed the original version of Apache Kafka and Apache Samza and Yahoo contributed Storm. And there are some amazing start-ups that are building and supporting important stream analytics tools such as Flink from Data-Artisans. Related university research includes systems like Neptune from Colorado State. I will post more about all of these tools later, but in this article I will describe my experience with the Microsoft EventHub, Stream Analytics and AzureML. What I will show below is the following
- It is relatively easy to build a streaming analytics pipeline with these tools.
- It works, but the performance behavior of the system is a bit uneven with long initial latencies and a serious bottleneck which is probably the result of small size of my experiment.
- AzureML services scale nicely
- Finally there are some interesting ways in which blocking can greatly improve performance.
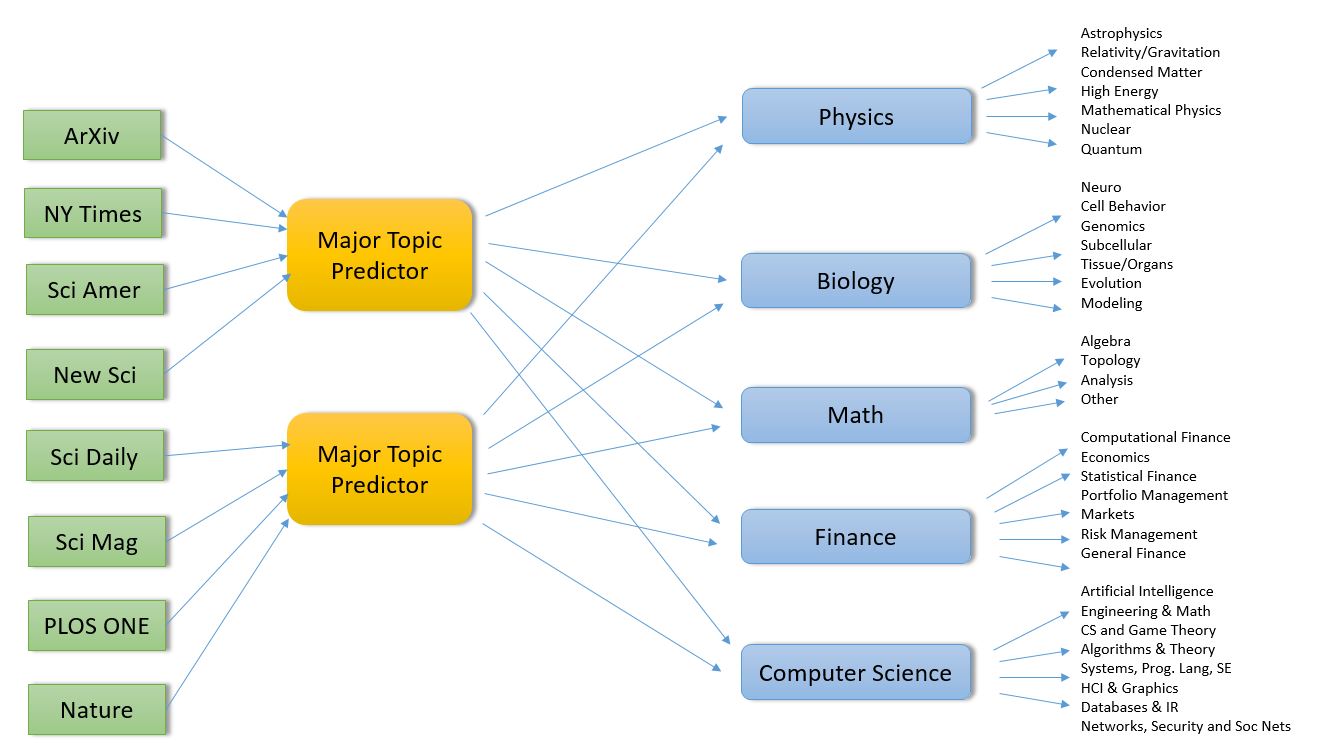
In a previous post I described how to use AzureML to create a version of a science document analyzer that I originally put together using Python Scikit-Learn, Docker and Mesosphere. That little project is described in another post. The streaming challenge here is very simple. We have data that comes from RSS feeds concerning the publication of scientific papers. The machine learning part of this is to use the abstract of the paper to automatically classify the paper into scientific categories. At the top level these categories are “Physics”, “math”, “compsci”, “biology”, “finance”. Big streaming data challenges that you find in industry and science involve the analysis of events that may be large and arrive at the rate of millions per second. While there are a lot of scientists writing lots papers, they don’t write papers that fast. The science RSS feeds I pull from are generating about 100 articles per day. That is a mere trickle. So to really push throughput experiments I grabbed several thousands of these records and wrote a simple server that would push them as fast as possible to the analysis service.
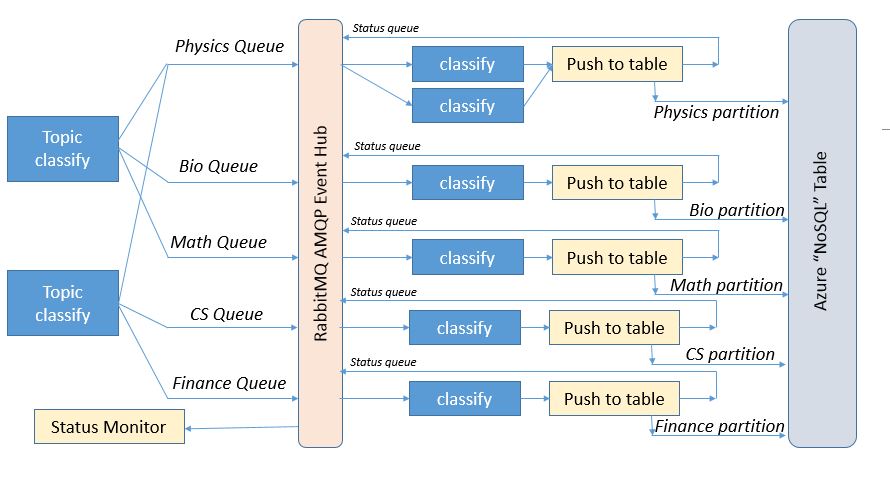
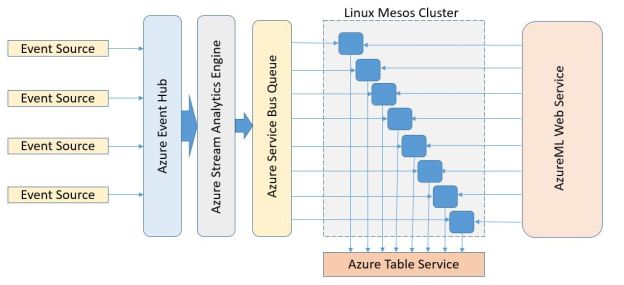
In this new version described here I want to see what sort of performance I could get from AzureML and Azure Stream Analytics. To accomplish this goal I set up the pipeline shown in Figure 1.
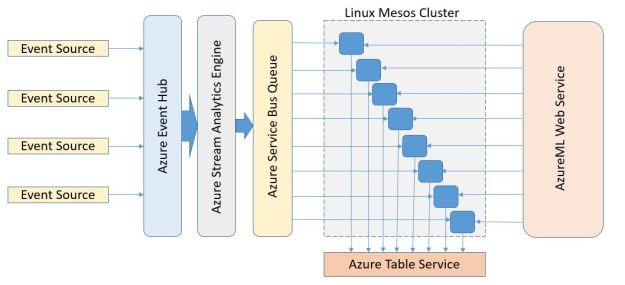
Figure 1. Stream event pipeline
As shown in the diagram events (document abstracts) are initially pushed into the event hub which is configured as the source for the stream analytics engine. The analytics engine does some initial processing of the data and then pushes the events to a message queue in the Azure Message Bus. The events are then pulled from the queue by a collection of simple microservices which call the AzureML classifier and then push the result of the call into the azure table service.
In the following paragraphs I will describe how each stage of this pipeline was configured and I will conclude with some rather surprising throughput results.
Pushing events into the Event Hub.
To get the events into the Event Hub we use a modified version the solution posted by Olaf Loogman. Loogman’s post provides an excellent discussion of how to get an event stream from the Arduino Yun and the Azure event hub using a bit of C and Python code. Unfortunately the Python code does not work with the most current release of the Python Azure SDK[1], but it works fine with the old one. In our case all that we needed to do was modify Loogman’s code to read our ArXiv RSS feed data and convert it into a simple JSON object form
{ ‘doc’: ‘the body of the paper abstract’,
‘class’: ‘one of classes:Physics, math, compsci, bio, finance’,
‘title’: ‘ the title of the paper’
}
The Python JSON encoder is very picky so it is necessary to clean a lot of special characters out of the abstracts and titles. Once that is done it is easy to push the stream of documents to the Event Hub[2].
According to Microsoft, the Event Hub is capable of consuming many millions of events per second. My simple Python publisher was only able to push about 4 events per second to the hub, but by running four publisher instances I was up to 16 eps. It was clear to me that it would scale to whatever I needed.
The Stream Analytics Engine
The Azure stream analytics engine, which is a product version of the Trill research project, has a very powerful engine for doing on-line stream processing. There are three things you must do to configure the analytics engine for your application. First you must tell it where to get its input. There are three basic choices: the event hub, blob storage and the “IOT” hub. I configured it to pull from my event hub channel. The second task is to tell the engine where to put the output. Here you have more choices. The output can go to a message queue, a message topic, blob or table storage or a SQL database. I directed it to a message queue. The final thing you must do is configure the query processing step you wish the engine to do. For the performance tests described here I use the most basic query which simply passes the data from the event hub directly to the message queue. The T-SQL code for this is
SELECT
*
INTO
eventtoqueue
FROM
streampuller
where eventtoqueue is the alias for my message bus queue endpoint and streampuller is the alias for my event queue endpoint. The original JSON object that went into the event hub emerges with top level objects which include the times stamps of the event entry and exit as shown below.
{ "doc": "body of the abstract",
"class": "Physics",
"title":"title of the paper",
"EventProcessedUtcTime":"2015-12-05T20:27:07.9101726Z",
"PartitionId":10,
"EventEnqueuedUtcTime":"2015-12-05T20:27:07.7660000Z"
}
The real power of the Analytics Engine is not being used in our example but we could have done some interesting things with it. For example, if we wanted to focus our analysis only on the Biology documents in the stream, that would only require a trivial change to the query.
SELECT
*
INTO
eventtoqueue
FROM
streampuller
WHERE class = ‘bio’
Or we could create a tumbling window and group select events together for processing as a block. (I will return to this later.) To learn more about the Azure Analytics Engine and T-SQL a good tutorial is a real-time fraud detection example.
Pulling events from the queue and invoking the AzureML service
To get the document events from the message queue so that we can push them to the AzureML document classifier we need to write a small microservice to do this. The code is relatively straightforward, but a bit messy because it involves converting the object format from the text received from the message queue to extract the JSON object which is then converted to the list form required by the AzureML service. The response is then encoded in a form that can be stored in the table. All of this must be encapsulated in the appropriate level of error handling. The main loop is shown below and the full code is provided in Github.
def processevents(table_service, hostname, bus_service, url, api_key):
while True:
try:
msg = bus_service.receive_queue_message('tasks', peek_lock=False)
t = msg.body
#the message will be text containing a string with a json object
#if no json object it is an error. Look for the start of the object
start =t.find("{")
if start > 0:
t = t[start:]
jt = json.loads(t)
title = jt["title"].encode("ascii","ignore")
doc = jt["doc"].encode("ascii","ignore")
tclass = jt["class"].encode("ascii","ignore")
evtime = jt["EventEnqueuedUtcTime"].encode("ascii", "ignore")
datalist = [tclass, doc, title]
#send the datalist object to the AzureML classifier
try:
x = sendrequest(datalist, url, api_key)
#returned value is the best guess and
#2nd best guess for the class
best = x[0][1]
second = x[0][2]
#save the result in an Azure Table using the hash
# of the title as the rowkey
#and the hostname of this container as the table partition
rk = hash(title)
timstamp = str(int(time.time())%10000000)
item = {'PartitionKey': hostname, 'RowKey': str(rk),
'class':tclass, 'bestguess':best, 'secondguess':second,
'title': title, 'timestamp': timstamp, 'enqueued': evtime}
table_service.insert_entity('scimlevents', item)
except:
print "failed azureml call or table service error"
else:
print "invalid message from the bus"
except:
print "message queue error”
Performance results
Now that we have this pipeline the most interesting experiment is to see how well it will perform when we push a big stream of messages to it.
To push the throughput of the entire pipeline as high as possible we wanted as many instances of the microservice event puller as possible. So I deployed a Mesos Cluster with 8 dual core worker nodes and one manager node using the template provided here. To maximize parallelism for the AzureML service, three additional endpoints were created. The microservices were assigned one of the four AzureML service endpoints as evenly as possible.
We will measure the throughput in seconds per event or, more accurately, the average interval between event arrivals over a sliding window of 20 events. The chart below shows the seconds/event as the sliding window proceeds from the start of a stream to the end. The results were a bit surprising. The blue line represents one instance of the microservice and one input stream. As you can see there is a very slow startup and the performance levels out at about 1 second/event. The orange line is the performance with 12 microservice instances and four concurrent input streams. Again the startup was slow but the performance leveled off at about 4 events/sec.
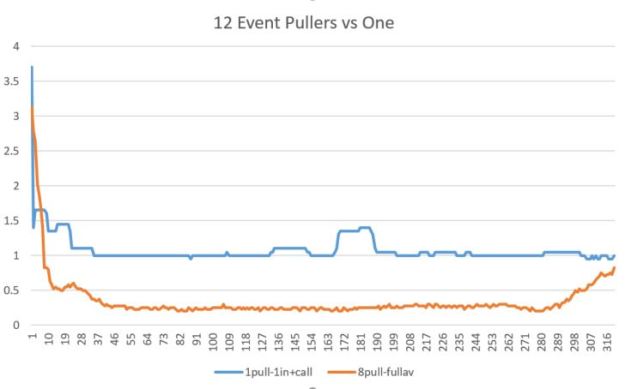
Figure 2. Performance in Seconds/Event with a sliding window of 20 events. Event number on the x-axis.
This raises two questions.
- Why the slow startup?
- Why the low performance for 12 instance case? Where is the bottleneck in the pipeline? Is it with the Azure Stream Analytics service, the message bus or the AzureML service?
Regarding the slow startup, I believe that the performance of the Azure services are scaled on demand. In other words, as a stream arrives at the event hub, resources are allocated to try to match the processing rate with the event arrival rate. For the first events the latency of the system is very large (it can be tens of seconds), but as the pool of unprocessed events grows in size the latency between event processing drops very fast. However, as the pool of unprocessed events grows smaller small resources are withdrawn and the latency goes back up again. (We pushed all the events into the event hub in the first minute of processing, so after that point the number in the hub declines. You can see the effect of this in the tail of the orange curve in Figure 2.) Of course, belief is not science. It is conjecture.
Now to find the bottleneck that is limiting performance. It is clear that some resources are not scaling to a level that will allow us to achieve more than 4 events/second with the current configuration. So I tried two experiments.
- Run the data stream through the event hub, message bus to the microservices but do not call the AzureML service. Compare that to the version where the AzureML service is called.
- Run the data stream directly into the message bus and do not call the AzureML service. Compare that one to the others.
The table below in Figure 3 refers to experiment 1. As you can see, the cost of the AzureML service is lost in the noise. For experiment 2 we see that the performance of the message bus alone was slightly worse that the message bus plus the eventhub and stream analytics. However, I expect these slight differences are not statistically significant.
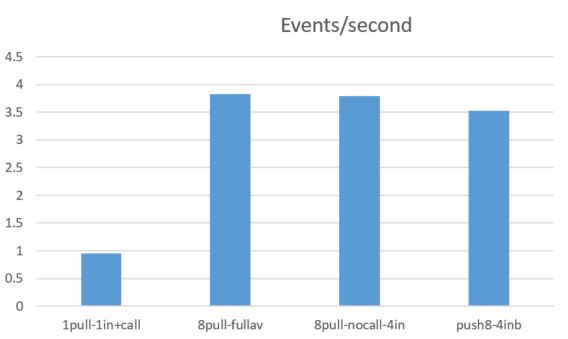
Figure 3. Average events per second compairing one microservice instance and one input stream to 8 microservices and 4 input streams to 8 microservices and 4 input streams with no call to AzureML and 8 microservices with 4 input streams and bypassing the eventhub and stream analytics.
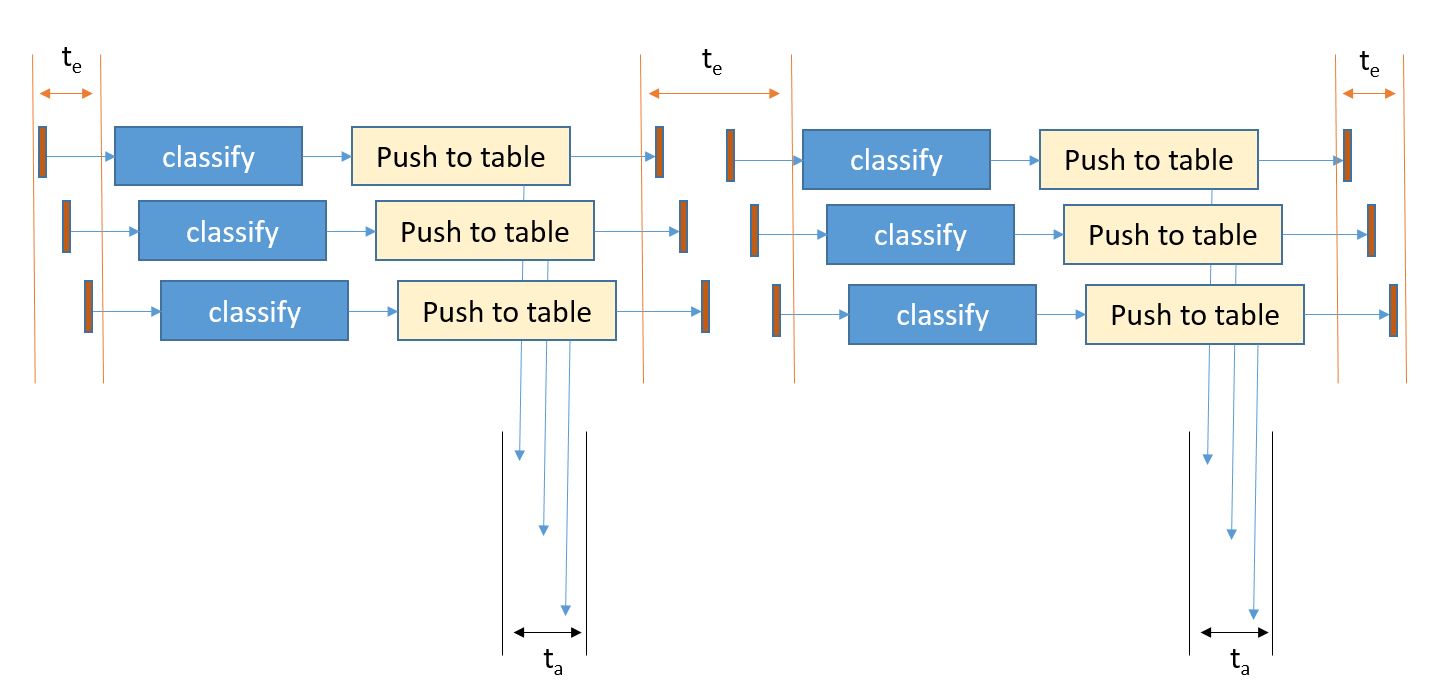
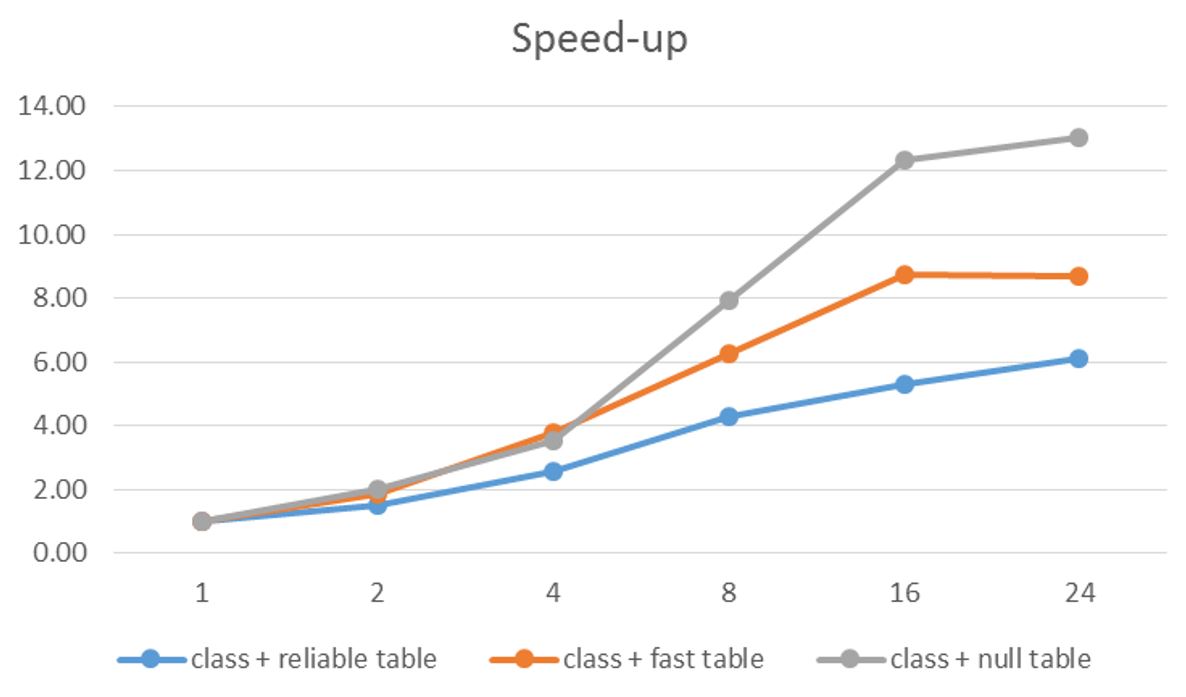
The bottom line is that the message bus is the bottleneck in the performance of our pipeline. If we want to ask the question how well the AzureML service scales independent of the message bus, we can replace it with the RabbitML AMQP server we have used in previous experiments. In this case we see a very different result. Our AzureML service demonstrates nearly linear speed-up in terms of events/sec. The test used an ancreasing number of microservices (1, 2, 4, 8, 12, 16 and 20) and four endpoints to the AzureML service. As can be seen in Figure 4 the performance improvement lessens when the number of microservice instances goes beyond 16. This is not surprising as there are only 8 servers running all 20 instances and there will be contention over shared resources such as the network interface.
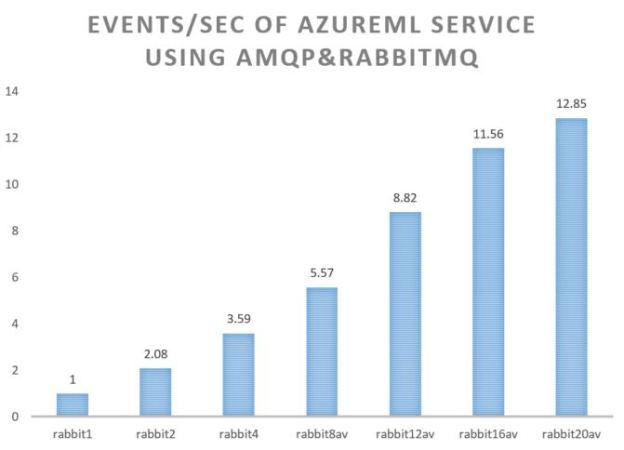
Figure 4. AzureML events per second using multiple microservice instances pulling the event stream from a RabbitMQ server instance running on a Linux server on Azure.
Takeaway
It was relatively easy to build a complete event analytics pipeline using the Azure EventHub, Azure Stream Analytics and to build a set of simple microservices that pull events from the message bus and invoke an AzureML service. Tests of the scalability of the service demonstrated that performance is limited by the performance of the Azure message bus. The AzureML service scaled very well when tested separately.
Because the Azure services seems to deliver performance based on demand (the greater the number unprocessed events in the EventHub, the greater the amount of resources that are provisioned to handle the load.) The result is a slow start but a steady improvement in response until a steady state is reached. When the unprocessed event pool starts to diminish the resources seem to be withdrawn and the processing latency grows. It is possible that the limits that I experience were because the volume of the event stream I generated was not great enough to warrant the resources to push the performance beyond 4 events/sec. It will require more experimentation to test that hypothesis.
It should also be noted that there are many other ways to scale these systems. For example, more message bus queues and multiple instances of the AzureML server. The EventHub is designed to ingest millions of events per second and the stream analytics should be able to support that. A good practice may be to use the Stream Analytics engine to filter the events or group events in a window into a single block which is easier to handle on the service side. The AzureML server has a block input mode which is capable of processing over 200 of our classification events per second, so it should be possible to scale the performance of the pipeline up a great deal.
[1] The Microsoft Azure Python folks seem to have changed the namespaces around for the Azure SDK. I am sure it is fairly easy to sort this out, but I just used the old version.
[2] The source code is “run_sciml_to_event_hub.py” in GitHub for those interested in the little details.