

I recently had the pleasure of attending two excellent workshops on the topic of streaming data analytics and science. A goal of the workshops was to understand the state of the art of “big data” streaming applications in scientific research and, if possible, identify common themes and challenges. Called Stream2015 and Stream2016, these meetings were organized by Geoffrey Fox, Lavanya Ramakrishnan and Shantenu Jha. The talks at the workshop were from an excellent collection of scientists from universities and the national labs and professional software engineers who are building cloud-scale streaming data tools for the Internet industry.
First it is important to understand what we mean by streaming data analytics and why it has become so important. Most scientific data analysis involves “data at rest”: data that was generated by a physical experiment or simulation and saved in files in some storage system. That data is then analyzed, visualized and summarized by various researchers over a period of time. The sizes of scientific data archives are growing and the number of disciplines creating new ones is expanding. New organizations like the Research Data Alliance have been created to help coordinate the development and sharing of scientific data collections. However not all data is “at rest” in this sense. Sometimes data takes the form of an unbounded stream of information. For example, the continuous stream of live instrument data from on-line sensors or other “internet of things” (IoT) devices. Even computer system logs can produce large continuous streams. Other examples include data from continuously running experiments or automated observatories such as radio telescopes or the output of DNA sequencers.
In some cases, the volume and rate of generation is so large, we cannot keep the data at rest for very long. The observed data from the Square Kilometer Array (SKA) will be so large that that it is too expensive to contemplate keeping it and therefore it must be immediately processed into a reduced stream. An important aspect of this large scale streaming scientific data analysis is computational steering: the need for a human or smart processes to analyze the data stream for quality or relevance and then to make rapid adjustments to the source instruments or simulations. The report from the first Streams workshop describes many of these cases. For example, autonomous vehicles processing radar data streams for oil and gas exploration or modern avionics systems that have to recognize bad data in real-time. Data coming from superconducting tokamak experiments must be managed and analyzed in real-time to adjust the control settings, and prevent catastrophic events.
This article has two parts. In this part we will look at the issue of streaming data in science and then present some of the lessons I gathered from the workshops. The workshop organizers have not released their final report for Stream2016, so their conclusions may be vastly different from my own. In the second part we take a deep dive into the cloud centric data analytics tools to try to understand the landscape of ideas and approaches that have evolved in recent years in this community.
There are many factors that determine when a particular technology is appropriate for a particular problem. Streaming data analytics is an interesting case that illustrates how diverse challenges and requirements have led software designers to build vastly different solutions. For example, the software built to manage the vast Twitter data streams just can’t handle the analytic problems encountered when steering high-end electron microscopy experiments. It is worth trying to understand why this is the case.
We can divide the spectrum of streaming data scenarios into three basic categories
- The data streaming challenges that confront large enterprises when dealing the data from millions of users of Internet enabled devices. These might be the “click-streams” from browsers to search engines where it is critical to understand user sentiment or where to place advertisements based on previous user queries. The stream may be the vast logs of the behavior of systems with tens of thousands of active machines that need to be constantly monitored, scaled and serviced. In these cases, the individual events that make up the stream are often very small records of a few bytes in length.
- Large scale environmental or urban sensor networks such as wide-area earthquake sensor networks or the NSF Ocean Observatories Initiative or urban sensors networks such as those proposed in Chicago’s Array of Things project. These are very heterogeneous collection of data streams that may involve instruments with very different stream characteristics. For example, some small sensors may generate a high rate of small message while others may generate large bunches of large Mbyte-size messages in bursts such as you would see from an UAV surfacing and uploading many records. They may require intermediate analysis at various stages but final analysis “downstream”. Another good example is the stream of data from a swarm of robots that must be analyzed to avoid collision (see the paper by He, Kamburugamuve and Fox which describes this real-time challenge in detail.)
- The streams generated by very large experimental facilities like the Large Hadron Collider, Square Kilometer Array, the Advanced Photon Source and massive supercomputer simulations. These large scale scientific experiments can be extremely complex and involve large numbers of instruments or HPC simulations, multiple data analysis steps and a distributed set of collaborators. Most of the data analysis in these experiments are not like the pure streaming data challenges we see in items 1 and 2. The data streams are often extremely large file object that must move through complex laboratory networks. The orchestration of the streaming activity more accurately resembles workflow than data flow and often that workflow must allow a human in the loop.
While it is tempting to think that one solution paradigm can cover all the bases, this may not be the case. Cases 1 has led to an explosion of creativity in the open source community and several very significant Apache projects. These include Spark Streaming which has been derived from the Spark parallel data analysis system, Twitter’s Storm system which has been redesigned by Twitter as Heron, Apache Flink from the German Stratosphere project, Googles Dataflow (also see this article) which is becoming Apache Beam which will run on top of Flink and Spark. Other university projects include Neptune and the Granules project at Colorado State. In addition to Google Cloud dataflow other cloud providers include Amazon Kinesis, Azure Streaming and IBM Stream Analytics. (Are you confused yet? In the second part of this report we will describe many of these in much greater detail.)
It turns out that many of the tools described above for case 1 also apply to case 2 under certain conditions. The challenges arise in two areas. If the real-time demands of the application require very low latencies such as is required for various UAV challenges, some cloud solutions can be lacking. However, Kamburugamuve, Ekanayake, Pathirage and Fox demonstrate that Storm’s basic communication mechanisms can be vastly improved using collective communication that exploit shared memory and optimized routing to meet the demands of the robot swarm example mentioned above. The second challenge is if the size of the individual events in the stream is large (greater than a megabyte), such as you may find in many instruments that deal with image our sound object, it may not work at all with many of the systems designed with case 1 in mind. Algorithmic methods can be used to reduce the size so approximate methods can be used to identify events for deeper off-line analysis. In many of these instrument streaming cases it is necessary to do more processing of the stream “near the edge”. In other words, many small data sources can be “pre-analyzed” by processors very near the source. For example, the Apache Quark edge-analytics tools are designed to run in very small systems such as the Raspberry Pi.
Case 3 presents the greatest departure from the emerging open source tools. The ATLAS experiment on the Large Hadron Collider (LHC) has a large Monte Carlo simulation component and they have converted the processing of the data into a relatively fine-grained event stream, called the Atlas Event Service. A distributed workload manager, PanDA manages a global queue of analysis tasks that can be executed on a variety of platforms including Amazon and, in a specialized form called Yoda, on HPC systems.
At the other end of the application spectrum, massively parallel simulation model running on an exascale computer can generate vast amounts of data. Every few simulated time steps the program may generate a very large (50GB or more) data structure distributed over a thousand parallel processing elements. You can save a few of these to a file system, but it is now preferable to create a stream of these big objects and let another analysis system consume them directly. The state-of-the-art HPC I/O library, called ADIOS, provided a very simple, standard- looking API to the application programmer, but the back-end of ADIOS can be adapted to a variety of storage or networking layers while taking full advantage of the parallel I/O capabilities of the host system. One such back-end is facilitated by a networking layer, EVPath that provides the flow and control needed to handle such a massive stream. Another backend target for ADIOS is DataSpaces, a system for creating shared data structures between application across distributed systems. DataSpaces accomplishes this by mapping n-dimensional array objects to one dimension by using a distributed hash table and Hilbert space filling curves. Together these provide a variety of streaming abstractions to allow data to move from one HPC application to a variety of HPC data analysis and visualization tools as illustrated in Figure 1.
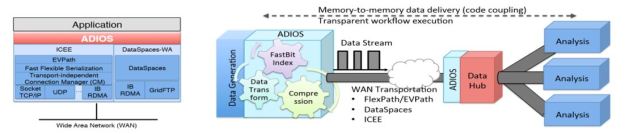
Figure 1. From “Stream Processing for Remote Collaborative Data Analysis” by Klasky, Chang, Choi, Churchill, Kurc, Parashar, Sim, Wolf and Wu. ORNL, PPPL, Rutgers, GT, SBU, UTK, LBNL. White paper Stream2016 workshop.
At the Streams 2016 workshop Kerstin Kleese Van Dam makes the important observation that that the workflow systems managing the stream analytics of time-critical experiments can be complex and the success of the experiment depends upon reliable performance of the overall system. The use case she described is “In Operando catalysis experiments”. More specifically, this involves the steering of high end electron microscopy experiments where a beam of electrons is transmitted through an ultra-thin specimen, interacting with the specimen as it passes through. These experiments can generate atomic resolution diffraction patterns, images and spectra under wide ranging environmental conditions. In-situ observations with these instruments, were physical, chemical or biological processes and phenomena are observed as they evolve. These experiments generate from 10GB-10’s of TB (e.g. at BNL) of data per at rates ranging from 100 images/sec for basic instruments to 1600 images/sec for state of the art systems. To optimize the scientific outcome of such experiments it is essential to analyze and interpret the results as they are emerging. It is essential that the workflow system reliably deliver optimal performance, especially in situations where time-critical decisions must be made or computing resources are limited.
The current systems in use include the Analysis in Motion framework developed by PNNL, but the challenge that is presented here is to enact the workflow in a way that yields reliable performance. The workflows are frequently composite applications built from loosely coupled parts, running on a loosely connected set of distributed and heterogeneous computational resources. Each workflow task may be designed for a different programming model and implemented in a different language, and most communicate via files sent over general purpose networks. This research group currently has a DOE project to demonstrate “Integrated End-to-End Performance Prediction and Diagnosis for Extreme Scientific Workflows (IPPD)”.
Concluding Observations.
The streaming data landscape is very new and evolving fast. I have come to the conclusion that of the three application domains described above (1: Internet Data Analysis, 2: Array of Things Instruments, 3: Big Science) only 1 and 2 are starting to see convergence of lines of thought and models of computing while 3 will always be driven by very different requirements and needs. The bleeding edge of science does not have the deep pockets of Google or Amazon when it comes to IT resources. Their budgets are dominated by the massive experimental facilities and supercomputers and hence the solutions must be custom. And each experimental domain is unique enough that few common tools beyond MPI exist. On the other hand, one can argue that Twitter, Google and all of the various Apache projects discussed here are also custom built for the problems they each are trying to solve. This is a world of “bespoke” software systems.
Algorithms and Analysis
An area where there will be great opportunity for sharing is in the algorithmic techniques that will be used to analyze the data. The Streams 2015 report observed that a variety of compelling research topics have emerged including adaptive sampling, online clustering, sketching and approximation that trade space and time complexity for accuracy. Sketching reduces an element of the stream to a basic form that allows easy generation of approximate answers to important queries. There are many forms of sketching. Szalay described an elegant way to do principal component analysis (PCA) is a streaming context. This provides a way to reduce the spectral complexity of a stream of big events. Machine Learning classifiers can and are used as part of stream analytics across application domains as diverse as tweet analysis and medical imaging. With the growing capabilities of deep learning systems, more data, images and sounds can be analyzed and recognized in near real-time. Skype can do near-real time natural language translation and face recognition from video streams. Applying the same technology to sifting through streams of instrument data will lead to new tools to understand earthquakes, hurricanes and tornadoes. We anticipate a lot of great work emerging from this area.
