
(Note: This is an updated version on 7/21/2016. The change relates to containers and HPC and it is discussed in the research topics at the end.)
I was recently invited to serve on a panel for the 2016 IEEE Cloud Conference. As part of that panel I was asked to put together 15 minutes on the state of cloud technology and pose a few research challenges. Several people asked me if I had published any of what I said so I decided to post my annotated notes from that mini-talk here. The slide deck that goes along with this can be found here. There were three others on the panel who each made some excellent points and this document does not necessarily reflect their views.
Cloud computing has been with us for fifteen years now and Amazon’s Web Services have been around for ten. The cloud was originally created to support on-line services such as email, search and e-commerce. Those activities generated vast amounts of data and the task of turning this data into value for the user has stimulated a revolution in data analytics and machine learning. The result of this revolution has been powerful and accurate spoken language recognition, near real-time natural language translation, image and scene recognition and the emergence of a first generation of cloud-based digital assistants and “smart” services. I want to touch on several aspects of cloud evolution related to these exciting changes.
Cloud Architecture
Cloud architectures have been rapidly evolving to support these computational and data intensive tasks. The cloud data centers of 2005 were built with racks of off-the-shelf server and standard networking gear, but the demands of the new workloads described above are pushing the cloud architects to consider some radically different approaches. The first changes were the introduction of software defined networks that greatly improved bisection bandwidth. This also allowed the data center to be rapidly reconfigured and repartitioned to support customer needs as well as higher throughput for parallel computing loads. Amazon was the first large public cloud vendor to introduce GPUs to better support high-end computation in the cloud and the other providers have followed suit. To accelerate the web search ranking process, Microsoft introduced FPGA accelerators and an overlay mesh-like network which adds an extra dimension of parallelism to large cloud applications.
The advent of truly large scale data collections made it possible to train very deep neural networks and all of the architectural advances described above have been essential for making progress in this area. Training deep neural nets requires vast amounts of liner algebra and highly parallel clusters with multiple GPUs per node have become critical enablers. Azure now support on-demand clusters of nodes with multiple GPUs and dedicated InfiniBand networks. The FPGAs introduced for accelerating search in the Microsoft data centers have also proved to be great accelerators for training convolutional neural networks. GPUs are great for training deep networks but Nirvana has designed a custom ASIC that they claim to be a better accelerator. Even Cray is now testing the waters of deep learning. To me, all of these advances in the architecture of cloud data centers points to a convergence with the trends in supercomputer design. The future exascale machines that are being designed for scientific computing may have a lot in common with the future cloud data centers. Who knows? They may be the same.
Cloud System Software
The software architecture of the cloud has gone through a related evolution. Along with software defined networking we are seeing the emergence of software defined storage. We have seen dramatic diversification in the types of storage systems available for the application developer. Storage models have evolved from simple blob stores like Amazon’s S3 to sophisticated distributed, replicated NoSQL stores designed for big data analytics such as Google’s BigTable and Amazon’s DynamoDB.
Processor virtualization has been synonymous with cloud computing. While this is largely still true, container technology like Docker has taken on a significant role because of its advantages in terms of management and speed of deployment. (It is worth noting that Google never used traditional virtualization in their data centers until their recent introduction of IaaS in GCloud.) Containers are used as a foundation for microservices; a style of building large distributed cloud applications from small, independently deployable components. Microservices provide a way to partition an application along deployment and language boundaries and they are well suited to Dev-Ops style application development.
Many of the largest applications running on the cloud by Microsoft, Amazon and Google are composed of hundreds to thousands of microservices. The major challenges presented by these applications are management and scalability. Data center operating systems tools have evolved to coordinate, monitor and attend to the life-cycle management of many concurrently executing applications, each of which is composed of vast swarms of containerized microservice. One such systems is Mesos from Mesosphere.
Cloud Machine Learning Tools
The data analytics needed to create the smart services of the future depend upon a combination of statistical and machine learning tools. Bayesian methods, random forests and others have been growing in popularity and are widely available in open source tools. For a long time, neural networks were limited to three levels of depth because the training methods failed to show improvements for deeper networks. But very large data collections and some interesting advances in training algorithms have made it possible to build very accurate networks with hundreds of layers. However, the computation involved in training a deep network can be massive. The kernels of the computation involve the dense linear algebra that GPUs are ideally suited and the type of parallelism in the emerging cloud architecture is well suited to this task. We now have a growing list of open source machine learning toolkits that have been recently released from the cloud computing research community. These include Amazon’s Tensorflow, AzureML, Microsoft Research Computational Network Tool Kit (CNTK), Amazon’s Deep Scalable Sparse Tensor Network Engine (DSSTNE), and Nervana’s NEON. Of course the academic research community has also been extremely productive in this area. Theano is an important Python toolkit that has been built with contributions from over a dozen universities and institutes.
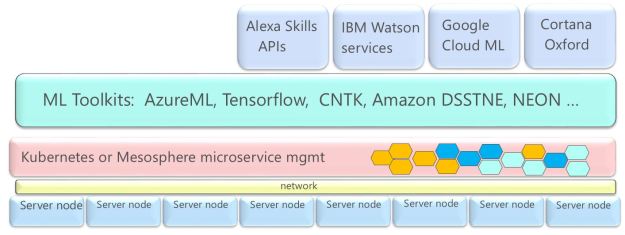
Figure 1. cloud ML tools and services stack
Not every customer of cloud-based data analytics wants to build and train ML models from scratch. Often the use cases for commercial customers are similar, hence another layer of services has emerged based on pre-trained models. The use cases include image and language recognition, specialized search, and voice-driven intelligent assistants. As illustrated in Figure 1, these new services include Cortana (and MSR project Oxford components), Google ML, Amazon Alexa Skills Kit, IBM Watson Services and (using a different style cloud stack) Sentient Aware.
Streaming Data Analytics Services
There are several “exponentials” that are driving the growth of cloud platforms and services. These include Big Data, mobile apps, and the Internet of things. The ability to analyze and act on data in motion is extremely important for application area including urban informatics, environmental and ecological monitoring and recovery, analysis of data from scientific experiments and web and data center log analysis. The Cloud providers and open source research community has developed a host of new infrastructure tools that can be used to manage massive streams of data from remote sources. These tools can be used to filter data streams, do on-line analysis and use the backend cloud machine learning services. The tools include Spark Streaming, Amazon Kinesis, Twitter Heron, Apache Flink, Google Dataflow/Apache Beam and the Azure Event hub and data lake. A more detailed analysis of these tools can be found here.
A Few Research Challenges
As was evident at the IEEE cloud conference, there is no shortage of excellent research going on, but as promised here are a few topics I find interesting.
- Cloud Data Center Architecture. If you are interested in architecture research the Open Compute Project has a number of challenging projects that are being undertaken by groups of researchers. They were founded by people from companies including Facebook, Intel, Google, Apple, Microsoft, Rackspace, Ericsson, Cisco, Juniper Networks and more and they have contributed open data center designs. And it is open, so anybody can participate.
- Cloud & Supercomputer convergence. As the sophistication of the cloud data centers approach that of the new and proposed supercomputers it is interesting to look at what architectural convergence might look like. For example, which modes of cloud application design will translate to supercomputers? Is it possible that the current microservice based approach to interactive cloud services could be of value to supercomputer centers? Can we engineer nanosecond inter-container messaging? Can we do a decent job of massive batch scheduling on the cloud with the same parallel efficiency as current supercomputers?
Update: It seems that there is already some great progress on this topic. The San Diego Supercomputer Center has just announced deployment of Singularity on two of their big machines. Singularity is a special container platform from Gregory M. Kurtzer of LBNL. There is a great article by Jeff Layton that gives a nice overview of Singularity. - Porting Deep Learning to Supercomputers. There is currently serious interest in doing large scale data analytics on large supercomputers such as those at the national centers. Some believe that the better algorithms will be available with these advance parallel machines. Can we compile tensorflow/CNTK/ DSSTNE using MPI for exascale class machines? In general, are there better ways to parallelize NN training algorithms for HPC platforms?
- The current open source stream analytics platforms describe above are designed to handle massive streams of events that are each relative small. However, many scientific event streams are more narrow and have event object that may be massive blobs. What would it take to modify the open source streaming tools to be broadly applicable to these “big science” use cases.
I welcome feedback on any of the items discussed here. Many of you know more about these topics than I, so let me know where you think I have incorrectly or overstated any point.

I just recently stumbled upon an article regarding Canonical Ubuntu’s work on LXC/LXD Linux Containers that I believe to be very relevant to HPC. In particular I agree with its conclusion that it would greatly benefit the HPC community with its bare metal approach and the efficiencies it provides. With a production-version set to release early next year, it may worthwhile to plan/evaluate the technology now for future deployment. https://www.nextplatform.com/2015/11/06/linux-containers-will-disrupt-virtualization-incumbents/
LikeLike
Thanks for the comment and link. Yes, this is very interesting. I am going to be interested to see what the reaction of the HPC community will be. So far the most interesting thing I have seen concerning containers used in HPC environments is Shifter https://www.nersc.gov/research-and-development/user-defined-images/ running on Cori at NERSC. They also have another system called Singularity, but I don’t know much about it yet. Speaking of HPC and containers, I am pleased to see NVidia-docker now allows containers to use GPUs. thanks again! i’ll see who is using LXC/LXD at SC this month.
LikeLike