

Abstract— This was originally written as an invited “vision” presentation for the eScience 2019 conference, but I decided to present something more focused for that event. Never wanting to let words go to waste I decided to put a revised version here. It was written as a look back at the period of eScience from 2019 to 2050. Of course, as it is being published in 2019, it is clearly a work of science fiction, but it is based on technology trends that seem relatively clear. Specifically, I consider the impact of four themes on eScience: the explosion of AI as an eScience enabler, quantum computing as a service in the cloud, DNA data storage in the cloud, and neuromorphic computing.
I. Introduction
Predictions of the future are often so colored by the present that they miss the boat entirely. The future, in these visions, tends to look like today but a bit nicer. Looking at images of the future from the 1950s we see pictures of personal helicopters (Figure 1) that clearly missed the mark. But in some cases, the ideas are not so far off, as in the case of the woman ordering shirts “online” as in Figure 2.

Fig 1. Future personal transportation. Mechanics Illustrated, Jan 1951

Fig 2. Shopping “online” vision.
To look at the evolution of eScience in the period from 2019 to 2050, it can help to look at the state of the art in computing in 1960 and ask how much of todays technology can we see emerging there. My first computer program was written when I was in high school. It was a Fortran version of “hello world” that consited of one line of Fortran per punched card as shown in Figure 3 and the entire program consisted of a deck of 12 cards .

Fig 3. The Fortran statement CALL RCLASS(AAA,21,NNC, PX3,PX4)
If asked to predict the future then, I might have said that software and data in the years ahead would be stored on a punched paper tape over ten miles long.
Fifty years ago, the high points of computing looked like:
- The programming language FORTRAN IV was created in 1961.
- IBM introduced its System/360. A monster machine.
- Gordon Moore makes an observation about scale in 1965 (that became Moore’s law).
- IBM created the first floppy disk in 1967.
- The SABRE database system that was used by IBM to help American Airlines manage its reservations data.
- In 1970 Edgar Codd came up with Relation Database Idea. It was not implemented until 1974.
- The Internet: a UCLA student, tries to send “login,” the first message over ARPANET, at 10:30 P.M. on October 29, 1969. (The system transmitted “l” and then “o” …. and then crashed.)
What we can extrapolate from this is that mainframe IBM computers will continue to dominate, databases are going to emerge as a powerful tool and there will be a future for computer-to-computer networking, but PCs and web search were not remotely visible on the horizon. The profound implication of Moore’s law would not be evident until the first microprocessors appear in 1979 and the personal computer revolution of the 1980s followed. Those same microprocessors led to the idea that dozens of them could be packaged into a “parallel computer”. This resulted in a period of intense research in universities and startups to build scalable parallel systems. While the first massively parallel computer was the Illiac IV which was deployed at NASA Ames in 1974, it was the work on clusters of microprocessors in the 1980s [1] that led to the supercomputers of 2019. Looking at computing in 1970, few would have guessed this profound transition in computing from mainframes like the System/360 to the massively parallel systems of 2019.
II. eScience from 2019 Forward
A. The Emergence and Evolution of the Cloud
The World Wide Web appeared in 1991 and the first search engines appeared in the mid 90s. As these systems evolved, so did the need to store large segments of the web on vast server farms. Ecommerce also drove the need for large data centers. These data centers quickly evolved to offering data storage and virtual machines as a service to external users. These clouds, as they became known, were designed to serve thousands to millions of concurrent clients in interactive sessions.
For eScience, clouds provided an important alternative to traditional batch-oriented supercomputers by supporting interactive, data exploration and collaboration at scale. The cloud data centers evolved in several important way. Tools like Google’s Kubernetes was widely deployed to support computation in the form of swarms of microservices built from software containers. Deploying Kubernetes still required allocating resources and configuring systems and microservices are continuously running processes. Serverless computing is a newer cloud capability that avoids the need to configure VMs to support long running processes when they are not needed.
Serverless computing is defined in terms of stateless functions that respond to events such as signals from remote instruments or changes in the state of a data archive. For examples, an eScience workflow can be automatically triggered when instrument data arrives in the data storage archive. The analysis in the workflow can trigger other serverless function to complete additional tasks.
The Cloud if 2019 is defined in terms of services and not raw hardware and data storage. These services include
- Streaming data analytics tools that allow the users to monitor hundreds of live streams from remote instruments. Edge computing services evolved as a mechanism to off-load some of the analytics to small devices that interposed between the instruments and the cloud.
- Planet scale databases allow a user to store and search data collections that are automatically replicated across multiple continents with guaranteed consistency.
- Services to support applications of machine learning became widely available across all the commercial public clouds. These services include speech recognition and generation, automatic language translation, computer vision tasks such as image recognition and automatic captioning.
The architecture of the cloud data centers continued to evolve toward ideas common in modern supercomputers. The first major change was the introduction of software defined networking throughout the data centers. Amazon began introducing GPU accelerators in 2012. This was followed by Google’s introduction of TPU chips to support the computational needs of deep learning algorithms coded in the Tensorflow system. The TPU (figure 4) is a device designed to accelerate matrix multiplication. It is based on systolic computation ideas of the 1980s and has been applied primarily to Google machine learning projects.

Fig 4. Google TPU v3 architecture. See N. Jouppi, C. Young, N. Patil, D. Patterson [2, 3].
The most radical evolutionary step has been taken by Microsoft in the Azure cloud. Project Brainwave represents an introduction of a mesh connected layer of FPGA devices that span the entire data center (figure 5). These devices can be programed to cooperate on parallel execution of lage computational task including serving deep learning models.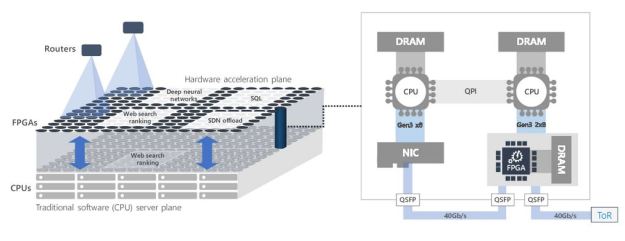 Fig 5. Microsoft FPGA based Project Brainwave [4, 5]
Fig 5. Microsoft FPGA based Project Brainwave [4, 5]
A. Major Themes Going Forward from 2019
The following pages will describe the four major themes that are going to dominate the ten years forward from 2019. They are
- The explosion of AI as an eScience enabler.
- Quantum computing as a service in the cloud.
- DNA data storage in the cloud.
- Neuromorphic computing
III. AI and eScience
Machine Learning went through a revolution in the years from 2008 to 2019 due to the intensive work at universities and in companies. The cloud providers including Google, Microsoft and others were driven by the need improve their search engines. Along the way they had amassed vast stores of text and images. Using this data and the new deep learning technologies they were able to build very powerful language translations systems and image recognition and captioning services that were mentioned above. By 2017, applications to eScience were beginning to emerge.
A. Generative Neural Networks and Scientific Discovery
One of the more fascinating developments that arose from the deep learning research was the rise of a special class of neural networks called generative models. The important property of these networks is that if you train them with a sufficiently, large and coherent collection of data samples, the network can be used to generate similar samples. These are most often seen in public as pernicious tools to create fake images and videos of important people saying things they never said.
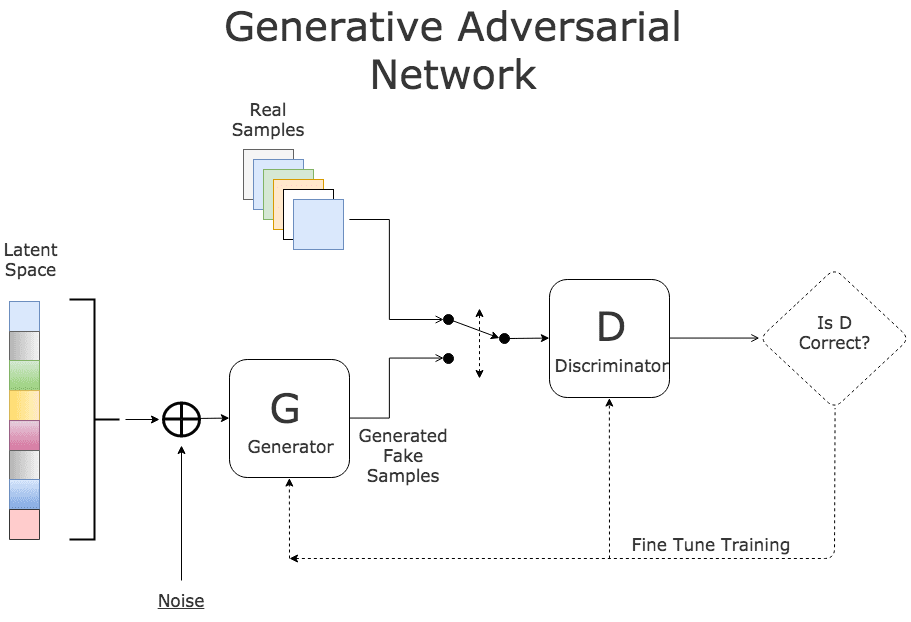
What these networks are doing is creating a statistical distribution of data that, when sampled, produces data that has properties that match nicely with the input data. When a scientist creates a simulation based on assumed parameters of nature, the simulations is evaluated against the statistical properties of the experimental observations. Generative models can be used to validate the simulation output in case the data is sparse. One of the most commonly used generative model is the Generative Adversarial Network (GAN) in which to networks are pitted against each other. As shown in Figure 6, a discriminator is trained to recognize the data that is from the real data set and a generator is designed to fool the discriminator. When converged the generator mimics the data distribution of the real data. There are several interesting examples of how generative models have been used in science. We list several in [6], but two that stand out are an application in astronomy and one in drug design.
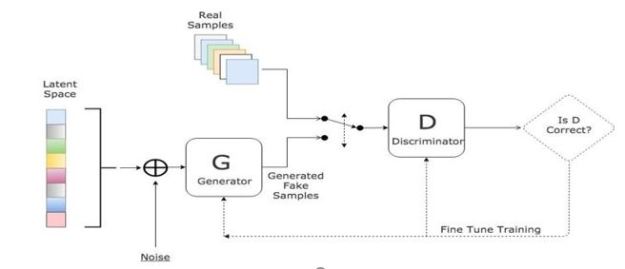
Fig 6. Generative Adversarial Network (GAN) from this site.
M. Mustafa, and colleagues demonstrate how a slightly-modified standard Generative Adversarial Network (GAN) can be used generate synthetic images of weak lensing convergence maps derived from N-body cosmological simulations [7]. The results illustrate how the generated images match their validation tests, but what is more important, the resulting images also pass a variety of statistical tests ranging from tests of the distribution of intensities to power spectrum analysis.
However, generative methods do not, by themselves, help with the problem of inferring the posterior distribution of the inputs to scientific simulations conditioned on the observed results, but there is value of in creating ‘life-like’ samples. F. Carminati, G. Khattak, S. Vallecorsa make the argument that designing and testing the next generation of sensors requires test data that is too expensive to compute with simulation . A well-tuned GAN can generate the test cases that fit the right statistical model at the rate needed for deployment [8].
In the area of drug design, Shahar Harel and Kira Radinsky have used a generative model to suggest chemical compounds that may be used as candidates for study [9]. They start with a prototype compound known to have some desirable properties. This is expressed as sequence and fed to a layer of a convolutional network that allow local structures to emerge as shorter vectors that are concatenated. A final all-to-all layer is used to generate sequence of mean and variance vectors for the prototype. his is fed to a “diversity layer” which add randomness as shown in Figure 7.
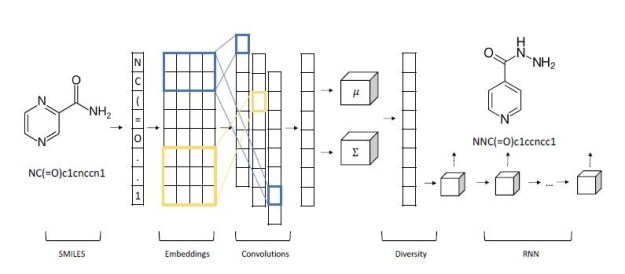
Fig 7. Shahar Harel and Kira Radinsky multi-layer generative netowork for drug design.
The decoder is an LSTM-based recurrent network which generates the new molecule. The results they report are impressive. In a one series of experiments they took as prototypes compounds from drugs that were discovered years ago, and they were able to generate more modern variations that are known to be more powerful and effective. No known drugs were used in the training.
B. Probabilistic Programming and Bayesian Inference
For very large experiments such as those conducted in the Large Hadron Collider, the scientists are interested in testing their models of the universe based the record of particle collisions that were generated. It is often the case that the scientists have a detailed simulation of the experimental system based on the current theoretical models of physics that are involved. These models are driven by setting parameters that correspond to assumptions about nature. When they run the experiment, they see new behaviors in the data, such as new particles emerging from collisions, and they would like to see which parameters when fed to the simulation can produce the output that corresponds to the experimental results. In other words, the simulation is a function taking parameters x to outputs y and the interesting question is given the outputs what the corresponding values for x. This is an inverse problem that is notoriously difficult to solve for large scientific problems. In terms of Bayesian statistics, they are interested in the posterior distribution P(x | y) where y is the experimental statistics.
In 2018 and later researchers began to study programming languages designed to express and solve problems like these. Pyro [10], Tensorflow Probability [11], and the Julia-based Gen [12] are a few of the Probabilistic Programing Languages (PPLs) introduced in 2019. One of the ideas in these languages is to build statistical models of behavior where program variables represent probability distributions and then, by looking at traces of the random choices associated with these variables during execution, one can make inferences about the random behaviors that influence outcomes.
These languages have been put in use in industries such as finance, their role in eScience is now becoming apparent. A. Güneş Baydin, et al. showed that PPLs can be used in very large Bayesian analysis of data from an LHC use case. Their approach allows a PPL too couple directly to existing scientific simulators through a cross-platform probabilistic execution protocol [13].
Probabilistic programming with PPLs will go on to become a standard tool used by eScientists.
C. AI-based Research Assistant
2018 was the year of the smart on-line bot and smart speaker. These were cloud based services that used natural language interfaces for both input and output. The smart speakers, equipped with microphones listen for trigger phrases like “Hello Siri” or “hello Google” or “Alexa” and recorded a query in English, extracted the intent and replied within a second. They could deliver weather reports, do web searches, keep your shopping list and keep track of your online shopping.
The impact of this bot technology will hit eScience when the AI software improves to the point that every scientist, graduate student and corporate executive had a person cloud-based research assistant. Raj Reddy calls these Cognition Amplifiers and Guardian Angels. Resembling a smart speaker or desktop/phone app, the research assistant is responsible for the following tasks:
- Cataloging research data, papers and articles associated with its owner’s projects. The assistant will monitor the research literature looking for papers exploring the same concepts seen in the owner’s work.
- Coordinate meetings among collaborators and establish coordination among other research assistants.
- Automatically sifting through other data from collaborators and open source archives that may be of potential use in current projects.
- Understanding the mathematical analysis in the notes generated by the scientist and using that understanding to check proofs and automatically propose simulators and experiment designs capable of testing hypotheses implied by the research.
From the perspective of 2019 eScience, the claim that the Research Assistant of the future will be able to derive simulations and plan experiments may seem a bit “over the top”. However, progress on automatic code completion and generation was making great strides in 2019. Transformers [16] provide a second generation of sequence-to-sequence AI tools that outpaced the recurrent neural networks previously used. Advances in programming tools based on similar technology show that AI can be used to generate code completions for C# method calls based on deep semantic mining of online archives of use cases.
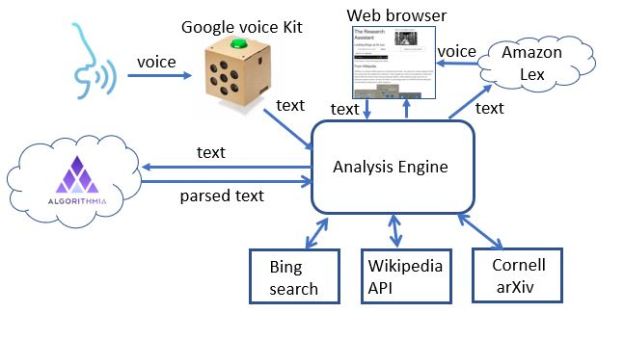
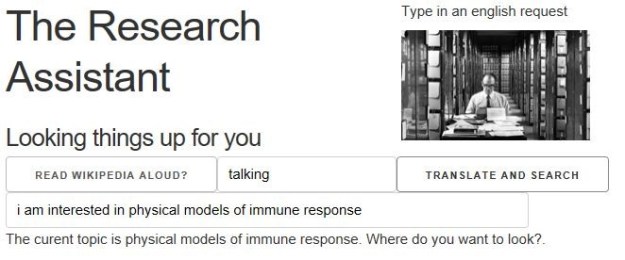
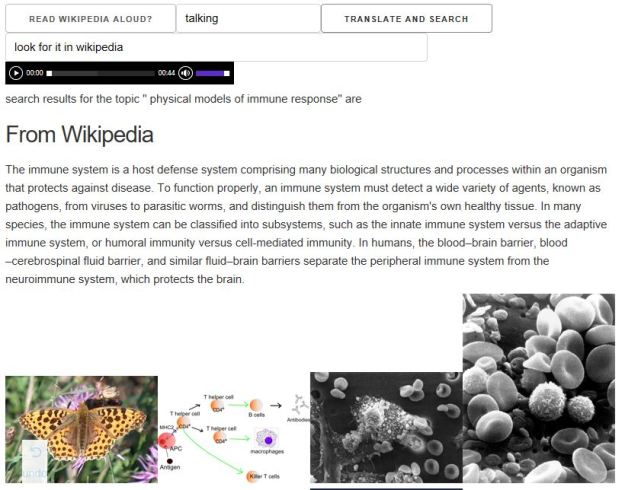
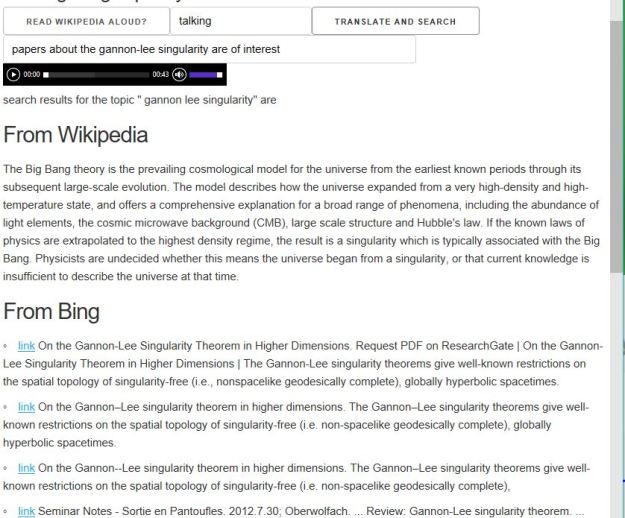
We built a toy demo of the Research Assistant in [14] that could take natural language (spoken or typed) input and find related research articles from Bing, Wikipedia and ArXiv (see Figure 6.)
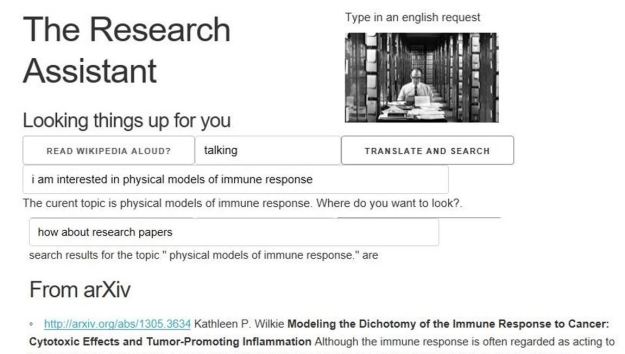
Fig 6. Demo cloud-based “research assistant” [14]
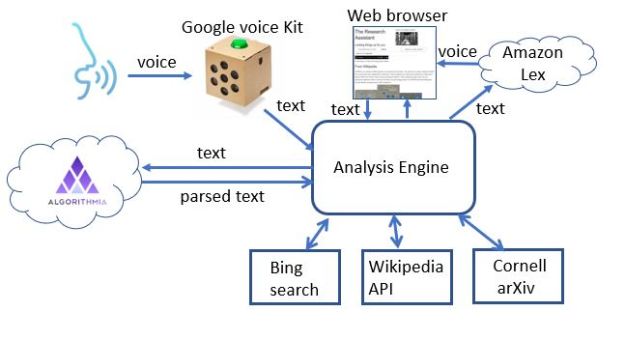
This demo prototype research assistant was built by composing a few cloud tools as shown in Figure 7. A much more sophisticated version can be built using a modern chatbot tool like RASA, but that will not address everything that is needed to reach the final goal.
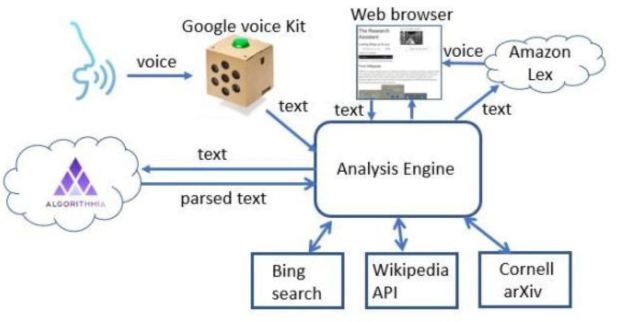
Fig 7. The toy research assistant demo is hosted an “elegant” cardboard container from Google’s voice kit running a python script on raspberry Pi. It invokes Googles speech to text, a text analysis service running on Algorithmia and uses Amazon’s Lex to generate voice. Depending on context, calls are made to Bing, Wikipedia or ArXiv.
While this demo was a toy, there has been serious work over the last few years to make progress on this topic. In 2018, Google introduced its Dataset Search service to provide easy data set discovery. The work of the Allen Institute for AI stands out [15]. Their Semantic Sanity project is a sophisticated research search engine that allows you to tell it basic topics that interest you and it will monitor ArXiv looking for important related contributions. Aristo is “an intelligent system that reads, learns, and reasons about science”. It can reason about diagrams, math and understand and answer elementary school science questions.
One important problem that must be solved is extracting non-trivial mathematical concepts from research papers and notes so that similar papers can be found. In addition to Semantic Sanity, there is some other early related work on this problem. For example, researchers are using unsupervised neural net to sift through PubChem and uses NLP techniques to identify potential components for materials synthesis [22].
IV. The Rise of Quantum in the Cloud
Long viewed as a subject of purely theoretical interest, quantum computing emerged in 2018 as a service in the cloud. By 2019, Rigetti, IBM, D-Wave and Alibaba had live quantum computing services available. Google and Microsoft followed soon after that. The approaches taken to building a quantum computer differed in many respects.
The basic unit of quantum computing is the qubit which obeys some important and non-intuitive laws of physics. Multiple qubits can be put into an “entangled” state in which an observation about one can effect the state of the others even when they are physically separated. One can apply various operators to qubits and pairs of qubits to form “logical” circuits and these circuits are the stuff of quantum algorithms. A fact of life about quantum states is that once you measure them, they are reduced to ordinary bits. However, the probability that a bit is reduced to a zero or a one is determined by the unmeasured quantum state of the system. A good quantum algorithm is one in which the quantum circuit produces outputs with a probability distribution that makes solving a specific problem very fast.
The first important quantum computations involved solving problems in quantum chemistry. In fact, this was the role that Richard Feynman had suggested for a quantum computer when he first came up with the idea in the 1980s. The other area of eScience that quantum computers excelled at was certain classes of optimization problems.
Early quantum computers are program by literally composing the quantum gates as illustrated in Figure 8.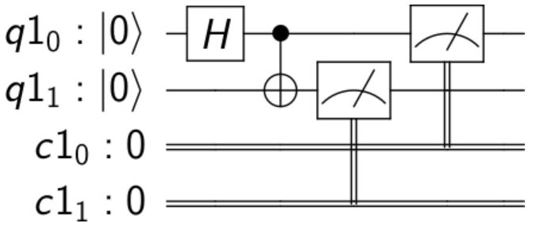
Fig 8. A simple quantum circuit to create an entangled pair of two qubits and measure the result
Programming tools to build such circuits include IBM’s IBM-Q qiskit and Microsoft’s Q# language and compiler. The IBM hardware was based what they call “noisy intermediate-scale quantum computers (NISQ)”. As shown in Figure 9, the induvial qubits are non-linear oscillators. Tuned superconducting resonator channels are used for readout. Also, the qubits are tied together by additional superconducting channels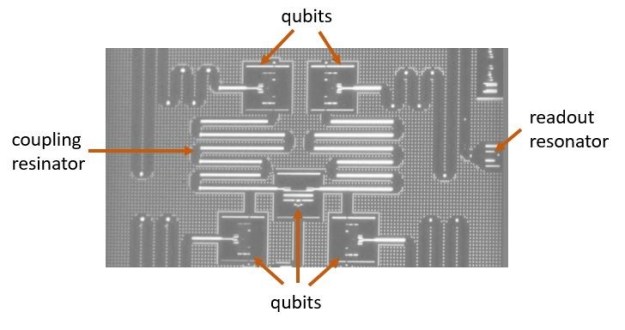
Fig 9 An early 5-qubit IBM-Q computational unit. Source: IBM-Q website.
One problem with early quantum systems is that the qubits are very susceptible to noise and degrade quickly. In other words, the error rate of quantum algorithms can be very high. The deeper the quantum circuit (the number of layers of “gates”), the more noise. A way around this is to add error-correcting redundancy into the circuit, but this means more qubits are required. Quantum volume refers to a measure of the number of qubits needed for the error-corrected circuit times the depth of the corrected circuit. Unfortunately, early quantum computers had very low bounds on achievable quantum volume.
Microsoft took a different approach to building qubits that are based on the topological property of woven threads. These are much more noise resistant and hence capable of building deeper circuits with less error correction.
IV. DNA-Based Storage
There are two problems with 2019 era storage technologies. First, it was not very stable. Data degrades and storage devices fail. Second, there was not enough storage capacity to capture the data that was being generated. 2.5 quintillion bytes of data was generated each day in 2018. Even if you cast out 99.9% of this as being of no long-term value, the remainder still leaves 2.5e+15 bytes per day. The amount of data stored in the cloud in 2018 was 1.0e+18 (an exabyte). In other words, the cloud only held 400 days’ worth of the important data. Obviously, another order or magnitude or more of the data needed to be discarded to allow the data centers time to expand to contain this growth. A new storage technology was needed.
DNA storage was first proposed in the 1960, but not much happened with the idea until 1988 when researchers from Harvard stored an image in the DNA of e.coli. By 2015 researchers at Columbia University published a method that allowed the storage of 215 petabytes (2.15e+17) of data per gram of DNA. And DNA is very stable over long periods of time. While this was promising, there was still a big problem. The encoding and decoding of the data were still an expensive manual process and it was not practical to have lab scientists running around in the back rooms of data centers managing wet processes.
In 2019, researchers at the University of Washington and Microsoft demonstrated an automated lab that could encode and decode data to DNA without human hands. The system works by converting the ones and zeros of digital data into the As, Ts, Cs and Gs that make up the building blocks of DNA. These encoded sequences are then fed into synthesizing systems. Their next breakthrough was to reduce the entire “lab” to a chip that uses microfluidics to route droplets of water around a grid to enact the needed chemistry steps. They also produced a sophisticated software stack called puddle that allow the scientist to program this with conventional high-level languages [20].
Other research has demonstrated ways in which DNA encoded data could be searched and structured in ways like relational databases. As the costs came down, this became the standard cloud storage technology.
VI. Neuromorphic Computing
It was long a dream of computer designers to build systems that mimicked the connectome of the biological brain. A major research initiative in Europe, the Human Brain Project, looked at the possibility of simulation a brain on traditional supercomputers. As that proved unrealistic, they turned to the study of special hardware devices that can simulate the behavior of neuron. Technology to build artificial neurons progressed in university and industry labs. The Stanford neurogrid can simulate six billion synapses. In 2017 Intel introduced the Loihi neuromorphic research test chip. The device is a many-core mesh of 128 neuromorphic cores and each of which contains 1,024 primitive spiking neural units. The neural units are current-based synapse leaky integrate-and-fire neurons [21].
In addition to the Loihi chip, Intel has released Pohoiki Beach, a system comprised of 64 Loihi chips and a substantial software stack to allow application development. Because overall power consumption is 100 times lower than GPU based neural networks, Intel’s application target is autonomous vehicles and robots. While full realization of true biological brain-like functionality may not be realized until the 2nd half of the 21st century, it is none the less an exciting step forward.
VII. Conclusions
EScientists in 2019 found themselves at an important inflection point in terms of the technology they could deploy in doing science. The cloud has evolved into a massive on-line, on-demand, heterogeneous supercomputer. It not only supports traditional digital simulation; it will also support hybrid quantum-digital computation. It will soon allow applications to interact with robotic sensor nets controlled by neuromorphic fabrics. Storage of research data will be limitless and backed up by DNA based archives.
One of the most remarkable features of computing in the 21st century has been the evolution of software. Programming tools have evolved into very deep stacks that have used and exploited AI methods to enable scientific programmer to accomplish more with a few lines of Julia in a Juypter notebook than was remotely possible programming computers of 1980. New probabilistic programming languages that combine large scale simulation with deep neural networks show promise of making Bayesian inference an easy to use used tool in eScience.
The role of AI was not limited to the programming and execution of eScience experiments. Users of the AI research assistants in 2050 can look back at the “smart speakers” of 2019 and view them as laughably primitive as the users of the 2019 World Wide Web looked back at the 1970s era where computers were driven by programs written on decks of punched cards.
References
- G. Fox, R. Williams, P. Massina, “Parallel Computing Works!”, Morgan Kauffman, 1994.
- N. Jouppi, C. Young, N. Patil, D. Patterson, “A Domain-Specific Architecture for Deep Neural Networks”, Communications of the ACM, September 2018, Vol. 61 No. 9, Pages 50-59
- https://cloud.google.com/tpu/docs/images/tpu-sys-arch3.png
- Chung, et al. “Serving DNNs in Real Time at Datacenter Scale with Project Brainwave.” IEEE Micro 38 (2018): 8-20.
- Fowers et al., “A Configurable Cloud-Scale DNN Processor for Real-Time AI,” 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, 2018, pp. 1-14
- D. Gannon, “Science Applications of Generative Neural Networks”, https://esciencegroup.wordpress.com/2018/10/11/science-applications-of-generative-neural-networks/, 2018
- Mustafa, et. al. “Creating Virtual Universes Using Generative Adversarial Networks” (arXiv:1706.02390v2 [astro-ph.IM] 17 Aug 2018)
- Carminati, G. Khattak, S. Vallecorsa, “3D convolutional GAN for fast Simulation”, https://www.ixpug.org/images/docs/IXPUG_Annual_ Spring_Conference_2018/11-VALLECORSA-Machine-learning.pdf
- Harel and K. Radinsky, “Prototype-Based Compound Discovery using Deep Generative Models” http://kiraradinsky.com/files/acs-accelerating-prototype.pdf
- Bingham, et al, “Pyro: Deep universal probabilistic programming.” Journal of Machine Learning Research (2018).
- Tensorflow Probability, https://medium.com/tensorflow/an-introduction-to-probabilistic-programming-now-available-in-tensorflow-probability-6dcc003ca29e
- Gen, https://www.infoq.com/news/2019/07/mit-gen-probabilistic-programs
- Güneş Baydin, et al, “Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale”, arXiv:1907.03382v1
- Gannon, “Building a ‘ChatBot’ for Scientific Research”, https://esciencegroup.wordpress.com/2018/08/09/building-a-chatbot-for-scientific-research
- Allen Institute for AI, Semantic Sanity and Aristo, https://allenai.org/demos
- Vaswani et al., “Attention Is All You Need”, arXiv:1706.03762v5
- Chong, Hybrid Quantum-Classical Computing https://www.sigarch.org/hybrid-quantum-classical-computing/
- Shaydulin, et al., “A Hybrid Approach for Solving Optimization Problems on Small Quantum Computers,” in Computer, vol. 52, no. 6, pp. 18-26, June 2019.
- Takahashi, B. Nguyen, K. Strauss, L. Ceze, “Demonstration of End-to-End Automation of DNA Data Storage”, Nature Scientific Reports, vol. 9, no. 1, pp. 2045-2322, 2019
- Wellsey, et al., “Puddle: A Dynamic, Error-Correcting, Full-Stack Microfluidics Platform”, ASPLOS’19 , April 13–17, 2019.
- Intel Loihi Neurmorphic Chip. https://en.wikichip.org/wiki/intel/loihi
- E. Kim, et al., “Materials Synthesis Insights from Scientific Literature via Text Extraction and Machine Learning”, Chem. Mater. 2017 29219436-944









{kind=link}
{kind=link}