
In a pair of articles from last winter (first article, second article) we looked at Microsoft’s “Computational Network Toolkit” and compared it to Google’s Tensorflow. Microsoft has now released a major upgrade of the software and rebranded it as part of the Microsoft Cognitive Toolkit. This release is a major improvement over the initial release. Because these older articles still get a fair amount of web traffic we wanted to provide a proper update.
There are two major changes from the first release that you will see when you begin to look at the new release. First is that CNTK now has a very nice Python API and, second, the documentation and examples are excellent. The core concepts are the same as in the initial release. The original programming model was based on configuration scripts and that is still there, but it has been improved and renamed as “Brain Script”. Brain Script is still an excellent way to build custom networks, but we will focus on the Python API which is very well documented.
Installing the software from the binary builds is very easy on both Ubuntu Linux and Windows. The process is described in the CNTK github site. On a Linux machine, simply download the gziped tared binary and execute the installer.
$wget https://cntk.ai/'BinaryDrop/CNTK-2-0-beta2-0-Linux-64bit-CPU-Only.tar.gz’ $tar -xf CNTK-2-0-beta2-0-Linux-64bit-CPU-Only.tar.gz $cd cntk/Scripts/linux $./install-cntk.sh
This will install everything including a new version of Continuum’s Anaconda Python distribution. It will also create a directory called “repos’’. To start Jupyter in the correct conda environment do the following.
$source “your-path-to-cntk/activate-cntk" $cd ~/repos/cntk/bindings/python/tutorials $Jupyter notebook
A very similar set of commands will install CNTK on your Windows 10 box. (If you are running Jupyter on a virtual machine or in the cloud you will need additional arguments to the Jupyter notebook command such as “-ip 0.0.0.0 –no browser” and then then you can navigate you host browser to the VM ip address and port 8888. Of course, if it is a remote VM you should add a password. ) What you will see is an excellent set of tutorials as shown in Figure 1.
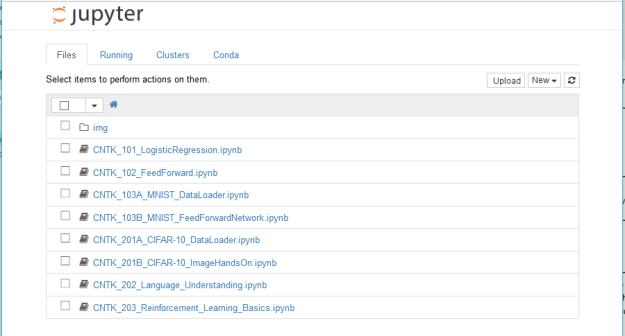
Figure 1. CNTK tutorial Jupyter notebooks.
CNTK Python API
CNTK is a tool for building networks and the Python and Brain Script bindings are very similar in this regard. You use the Python program to construct a network of tensors and then train and test that network through special operations which take advantage of underlying parallelism in the hardware such as multiple cores or multiple GPUs. You can load data into the network through Python Numpy arrays or files.
The concept of constructing a computation graph for later execution is not new. In fact, it is an established programming paradigm used in Spark, Tensorflow, and Python Dask. To illustrate this in CNTK consider the following code fragment that creates two variables and a constructs a trivial graph that does matrix vector multiplication and vector addition. We begin by creating three tensors that will hold the input values to the graph and then tie them to the matrix multiply operator and vector addition.
import numpy as np import cntk X = cntk.input_variable((1,2)) M = cntk.input_variable((2,3)) B = cntk.input_variable((1,3)) Y = cntk.times(X,M)+B
In this X is a 1×2 dimensional tensor, i.e. a vector of length 2 and M is a matrix that is 2×3 and B is a vector of length 3. The expression Y=X*M+B yields a vector of length 3. However, no computation has taken place. We have only constructed a graph of the computation. To invoke the graph we input values for X, B and M and then apply the “eval’’ operator on Y. We use Numpy arrays to initialize the tensors and supply a dictionary of bindings to the eval operator as follows
x = [[ np.asarray([[40,50]]) ]]
m = [[ np.asarray([[1, 2, 3], [4, 5, 6]]) ]]
b = [[ np.asarray([1., 1., 1.])]]
print(Y.eval({X:x, M: m, B: b}))
array([[[[ 241., 331., 421.]]]], dtype=float32)
CNTK has several other important tensor containers but two important ones are
- Constant(value=None, shape=None, dtype=None, device=None, name=”): a scalar, vector or other multi-dimensional tensor.
- Parameter(shape=None, init=None, dtype=None, device=None, name=”): a variable whose value is modified during network training.
There are many more tensor operators and we are not going to go into them here. However, one very important class is the set of operators that can be used to build multilevel neural networks. Called the “Layers Library’’ they form a critical part of CNTK. One of the most basic is the Dense(dim) layer which creates a fully connected layer of output dimension dim. As shown in Figure 2.
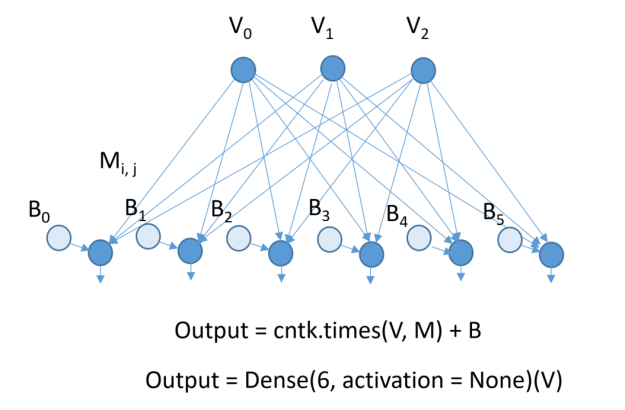
Figure 2. A fully connected layer created by the Dense operator with an implicit 3×6 matrix and a 1×6 vector of parameters labeled here M and B. The input dimension is taken from the input vector V. The activation here is the default (none), but it could be set to ReLu or Sigmod or another function.
There are many standard layer types including Convolutional, MaxPooling, AveragePooling and LSTM. Layers can also be stacked with a very simple operator called “sequential’’. Two examples taken directly from the documentation is a standard 4 level image recognition network based on convolutional layers.
with default_options(activation=relu):
conv_net = Sequential ([
# 3 layers of convolution and dimension reduction by pooling
Convolution((5,5), 32, pad=True), MaxPooling((3,3), strides=(2,2)),
Convolution((5,5), 32, pad=True), MaxPooling((3,3), strides=(2,2)),
Convolution((5,5), 64, pad=True), MaxPooling((3,3), strides=(2,2)),
# 2 dense layers for classification
Dense(64),
Dense(10, activation=None)
])
The other fun example is a slot tagger based on a recurrent LSTM network.
tagging_model = Sequential ([
Embedding(150), # embed into a 150-dimensional vector
Recurrence(LSTM(300)), # forward LSTM
Dense(labelDim) # word-wise classification
])
The Sequential operator can be thought of as a concatenation of the layers that in the given sequence. In the case of the slot tagger network, we see two additional important operators: Embedding and Recurrence.
Embedding is used for word embeddings where the inputs are sparse vectors of size equal to the word vocabulary (item i = 1 if the word is the i-th element of the vocabulary and 0 otherwise) and the embedding matrix is of size vocabulary-dimension by, in this case, 150. The embedding matrix may be passed as a parameter or learned as part of training.
The Recurrence operator is used to wrap the correct LSTM output back to the input for the next input to the network.
A Closer Look at One of Tutorials.
The paragraphs above are intended to give you the basic feel of what CNTK looks like with its new Python interface. The best way to learn more is to study the excellent example tutorials.
CNTK 203: Reinforcement Learning Basics
CNTK version 1 had several excellent tutorials, but version 2 has the Python notebook versions of these plus a few new ones. One of the newest demos is an example of reinforcement learning. This application of Neural Nets was first described in the paper Human-level control through deep reinforcement learning, by the Google DeepMind group. This idea has proven to be very successful in systems that learn to play games. This topic has received a lot of attention, so we were happy to see this tutorial included in CNTK. The example is a very simple game that involves balancing a stick. More specifically they use the cart-pole configuration from OpenAI. As shown in figure 3, the system state can be described by a 4-tuple: position of the cart, its velocity, the angle of the pole and the angular velocity. The idea of the game is simple. You either push the cart to the left or the right and see if you can keep the stick vertical. If you drift too far off course or the pole angle goes beyond an angle of 15 degrees, the game is over. Your score is the total number of steps you take before failure. The full example is in the github repository and we are not going to go through all the code here. The Jupyter notebook for this example is excellent, but if you are new to this topic you may find some additional explanation of value in case you decide to dig into it.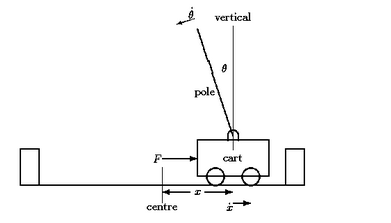
Figure 3. Cart-Pole game configuration.
The part of reinforcement learning used here is called a Deep Q-Network. It uses a neural network to predict the best move when the cart is in a given state. This is done by implicitly modeling a function Q(s,a) which is the optimal future reward given state s and the action is a and where the initial reward is r. They approximate Q(s,a) using the “Bellmann equation” which describes how to choose action a in a given state s to maximize the accumulated reward over time based inductively on the same function applied to the following states s’.
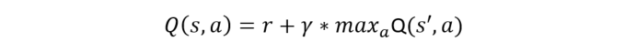
The parameter gamma is a damping factor that guarantees the recurrence converges. (Another excellent reference for this topic is the blog by Jaromír Janisch.) The CNTQ team approached this problem as follows. There are three classes.
- Class Brain. This hold our neural net and trainer. There are three methods
- Create() which is called at initialization. It creates the network. There are two tensor parameters: observation, which is used to hold the input state and q_target which is a tensor used for training. The network is nice and simple:
l1 = Dense(64, activation=relu) l2 = Dense(2) unbound_model = Sequential([l1, l2]) model = unbound_model(observation)
The training is by the usual stochastic gradient descent based on a loss measure.
loss = reduce_mean(square(model - q_target), axis=0) meas = reduce_mean(square(model - q_target), axis=0) learner = sgd(model.parameters, lr, gradient_clipping_threshold_per_sample=10) trainer = Trainer(model, loss, meas, learner) - Train(x, y) which calls the trainer for batches of states x and predicted outcomes y which we will describe below
- Predict(s) which invokes the model for state ‘s’ and returns a pair of optimal rewards given a left or right move.
- Create() which is called at initialization. It creates the network. There are two tensor parameters: observation, which is used to hold the input state and q_target which is a tensor used for training. The network is nice and simple:
- Class Memory. This hold a record of recent moves. This is used by the system to create training batches. There are two methods
- Add(sample configuration) – adds a four tuple consisting of a starting state, an action and a result and a resulting state tuple to a memory.
- Sample(n) returns a random sample of n configurations samples from the memory.
- Class Agent which is the actor that picks the moves and uses the memory to train the network. There are three methods here.
- Act(state) returns a 0 or 1 (left move or right move) that will give the best reward for the given state. At first it just makes random guesses, but as time passes it uses the Predict method of the Brain class to select the best move for the given state.
- Observe(sample configuration) records a configuration in the memory and keeps track of the time step and another parameter used by act.
- Replay() is the main function for doing the learning. This is the hardest part to understand in this tutorial. It works by grabbing a random batch of memorized configurations from memory. What we will do is use the current model to predict an optimal outcome and use that as the next step in training the model. More specifically for each tuple in the batch we want to turn it into a training sample so that the network behaves like the Bellmann equation. A tuple consists of the start state, the action, the reward and the following state. We can apply our current model to predict the award for the start state and also for the result state. We can use this information to create a new reward tuple for the given action and start state that models the Bellmann recurrence. Our training example is the pair consisting of the start state and this newly predicted reward. At first this is a pretty poor approximation, but amazingly over time it begins to converge. The pseudo code is shown below.
x = numpy.zeros((batchLen, 4)).astype(np.float32) y = numpy.zeros((batchLen, 2)).astype(np.float32) for i in range(batchLen): s, a, r, s_ = batch[i] # s = the original state (4 tuple) # a is the action that was taken # r is the reward that was given # s_ is the resulting state. # let t = the reward computed from current network for s # and let r_ be the reward computed for state s_. # now modify t[a] = r + gamma* numpy.amax(r_) # this last step emulated the bellmann equation x[i] = s y[i] = t self.brain.train(x,y)
The final part of the program is now very simple. We have an environment object that returns a new state and a done flag for each action the agent takes. We simply run our agent until it falls out of bounds (the environment object returns done=True). If the step succeeded, we increment our score. The function to run the agent and to keep score is shown below.
def run(agent):
s = env.reset()
R = 0
while True:
a = agent.act(s)
s_, r, done, info = env.step(a)
if done: # terminal state
s_ = None
agent.observe((s, a, r, s_))
agent.replay() #learn from the past
s = s_
R += r
if done:
return R
Each time we run “run” it learns a bit more. After about 7000 runs it will take over 600 steps without failure.
The text above is no substitute for a careful study of the actual code in the notebook. Also, as it is a notebook, you can have some fun experimenting with it. We did.
Final Thoughts
CNTK is now as easy to use as any of the other deep learning toolkits. While we have not benchmarked its performance they claim it is extremely fast and it make good use of multiple GPUs and even a cluster of servers. We are certain that the user community will enjoy using and contributing to its success.
Citation.
The team that first created CNTK should be cited. I know there are likely many others that have contributed to the open source release in one way or another, but the following is the master citation.
Amit Agarwal, Eldar Akchurin, Chris Basoglu, Guoguo Chen, Scott Cyphers, Jasha Droppo, Adam Eversole, Brian Guenter, Mark Hillebrand, T. Ryan Hoens, Xuedong Huang, Zhiheng Huang, Vladimir Ivanov, Alexey Kamenev, Philipp Kranen, Oleksii Kuchaiev, Wolfgang Manousek, Avner May, Bhaskar Mitra, Olivier Nano, Gaizka Navarro, Alexey Orlov, Hari Parthasarathi, Baolin Peng, Marko Radmilac, Alexey Reznichenko, Frank Seide, Michael L. Seltzer, Malcolm Slaney, Andreas Stolcke, Huaming Wang, Yongqiang Wang, Kaisheng Yao, Dong Yu, Yu Zhang, Geoffrey Zweig (in alphabetical order), “An Introduction to Computational Networks and the Computational Network Toolkit“, Microsoft Technical Report MSR-TR-2014-112, 2014.

Do you have any information (or perhaps a separate blog) on the C++ API?
LikeLike
sorry, I don’t have any information about the c++ api other than I read that they are working on one.
see https://github.com/Microsoft/CNTK/issues/193
In the github repo I see bindings for python and c#.
LikeLike