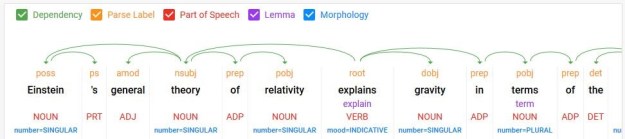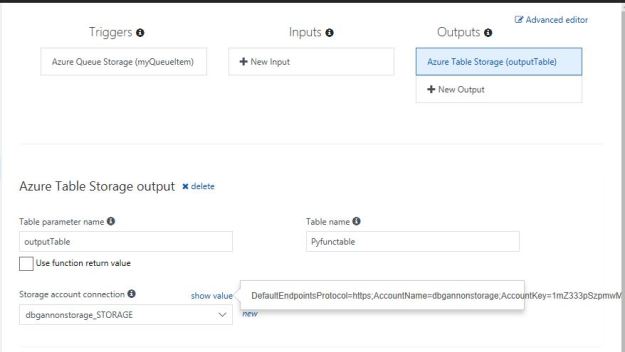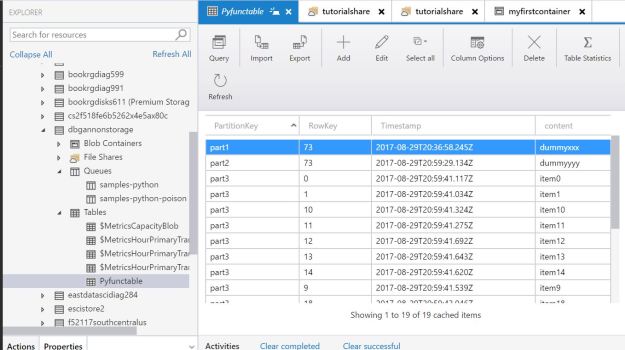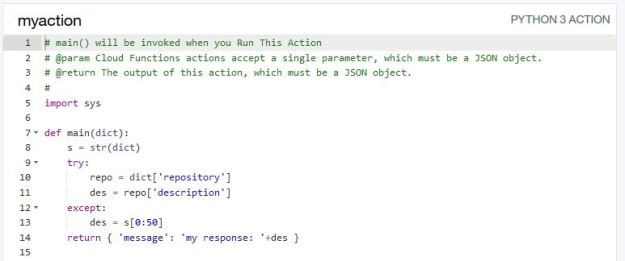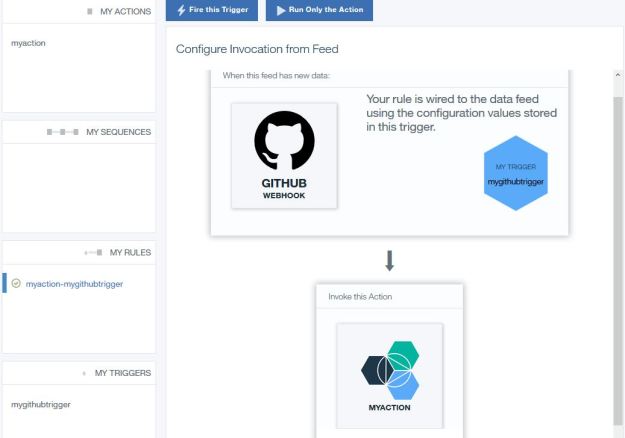
We can use Alexa, Cortana and Siri to check the weather, stream our favorite music and lookup facts like “who directed Casablanca?” But if I want to find all the research on quantum entanglement in the design of topological quantum computers, these services will fall short. If, in addition, I want these articles cataloged in my personal archive and the citations automatically pulled I need a much more robust digital assistant. Raj Reddy talks about a broader and more pervasive future for digital assistant he calls Cognition Amplifiers and Guardian Angels. In this post we look at chatbots and their limitations and show how to build a simple, voice-driven scientific metasearch tool we call the research assistant. Finally, we discuss the next phase of research assistant.
Smart Speakers and Chatbots.
The revolution in “smart speaker” digital assistants like Siri, Amazon Echo, Google Home is showing us the power of voice to provide input to smart cloud services. These assistants can take notes, tell us the weather conditions, place on-line orders for us and much more. I even allow Microsoft’s Cortana to read my email. If I send the message “I’ll get back to you tomorrow” to a friend, Cortana will remind me the next day that a response is needed. Amazon allows people to add “skill” (additional capabilities) to there Alexa system. These smart speakers are designed around open-ended question-response scenario. These assistants leverage very powerful speech-to-text technology and semantic analysis systems to extract a query or command. The query answers are derived from web-data analysis and the commands are to a limited number of native services (or external skills).
A chatbot is a system that engages the user in a dialog. They go beyond the question answering smart speakers and are usually designed to help people interact with the services of a specific company or agency. The Google, IBM, Amazon and Microsoft have all introduced cloud services to help anybody build a chatbot. These services guide you through the process of building and training a chatbot. A good example is Google’s Dialogflow. Using this tool to create a bot, you specify three things:
- Intents – which are mapping between what the user says and how you wish the system to respond.
- Entities – that are the categories of subjects that your bot understands. For example, if you bot is a front end to your clothing store, one category of entity my be product type: shoes, dress, pants, hats, and another entity might be size: large, xl, small, medium, and another might be color.
- Context – This is knowledge obtained by the bot during the course of the conversation. For example, the name of the user, or the users favorite shoe color.
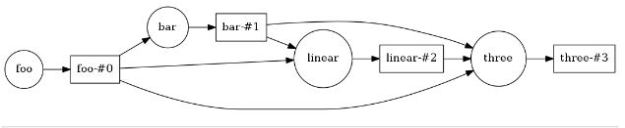
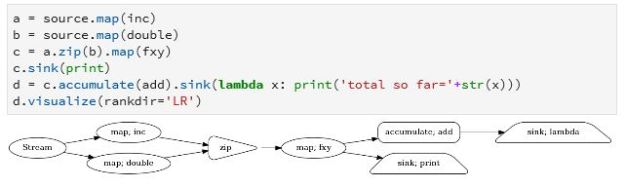
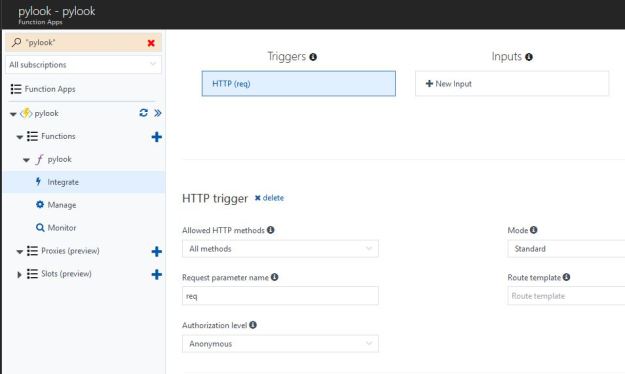
The goal of the bot is to extract enough information from the user to take a meaning action such as fulfilling an order. The hard part is designing the intents so that a dialog can lead to the desired conclusion. The resulting sysgtem is called an agent and the flow of action is illustrated in Figure 1. It might start with ‘Good morning, how can I help you?’ and end with a summary of the discussion. As the programmer you need to supply as many possible variations on possible user questions and responses as possible. And you must annotate these with makers where your entities can be extracted. Your examples are used in a training phase that maps your intents and entities together and builds a model that will learn variations on the input and not repeat the same sequence of responses each time, so it seems less robotic to the user.
Amazon’s Lex provides a similar service that also integrates with their lambda services. Microsoft has the Azure Bot Service and IBM has Watson assistant chatbot tools.
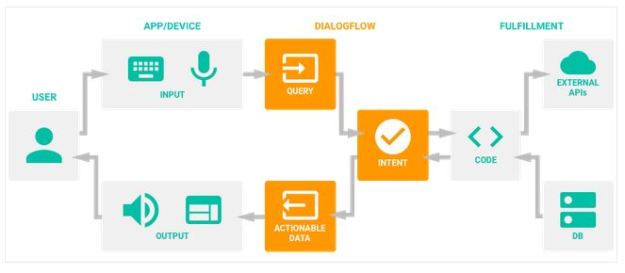
Figure 1. Google Dialogflow Agent architecture.
These tools are all designed to help you build a very focused conversation with the user about a very narrow universe such as the on-line part of a business. But this raises the question, can one build a chat bot that can carry out an open-ended conversation. Perhaps one that could pass the Turing test? The research literature on the subject is growing and deep learning tools like recurrent and convolutional neural networks have been applied to the problem (see https://arxiv.org/pdf/1606.07056.pdf , https://arxiv.org/pdf/1605.05110.pdf and more). Unfortunately chatbots designed to engage in open-ended conversation have only had a limited success. Xiaoice is one that interacts with users on the Chinese micro blogging service Weibo. The problem is that while it sounds like conversation, it is mindless. Microsoft’s Tay was an English language version that operated on Twitter until it was taken down after only 16 hours because of the unfortunate language it had learned. A successor Zo seems to be working better, but it does not produce conversations with intellectual content.
There is an excellent pair of articles by Denny Britz about the role of deep learning for conversational assistants. He make the point that for open-ended conversations (he calls them open-domain) the challenges are large compared to the fixed domain chatbots because so much more world knowledge is required.
Cognition Amplifiers and the Research Assistant.
In the spring of 2018 Raj Reddy gave the keynote presentation at the IEEE services congress. His topic was one he has addressed before and it clearly resonated with the audience. He described Cognition Amplifiers and Guardian Angels. He defined a Cognition Amplifier (COG) as a Personal Enduring Autonomic Intelligent Agent that anticipates what you want to do and help you to do it with less effort. A Guardian Angel (GAT) is a Personal Enduring Autonomic Intelligent Agent that discovers and warns you about unanticipated events that could impact your safety, security and happiness.
Consider now the application of the Cognition Amplifier to scientific research. If you are working on writing a research paper, you may wish your autonomic research assistant to provide a fast and accurate search of the scientific literature for a specific list of scientific concepts. In fact, as you write the paper, the assistant should be able to pick up the key concepts or issues and provide a real-time bibliography of related papers and these should be stored and indexed in a private space on the cloud. Extracting key phrases from technical documents is already a heavily research field so applying this technology to this problem is not a great leap. However, key phrase extraction is not the whole challenge. Take sentence “It seems that these days investors put a higher value on growth than they do on profitability”. The categorical topic is value of growth vs profitability – investor opinions which is not simply a key phrase, but a concept and we need the research assistant to look for concepts. Your research assistant should always understand and track the context of your projects.
Finally, a good research assistant for science should be able to help with the analytical part of science. For example, it should help locate public data in the cloud related to experiments involving your topics of interest. The assistant should be able to help formulate, launch and monitor data analysis workflows. Then coordinate and catalog the results.
And, of course, if your autonomous research assistant is also a Guardian Angel, it will also keep you informed of grant reporting deadlines and perhaps pull together a draft quarterly report for your funding agency.
I fully expect that it is possible to build such an agent in the years ahead. However, the remainder of this article is a simple demo that is a far cry from the full research assistant agent described above.
The Research Assistant Metasearch Tool.
In the following paragraphs we describe a very simple voice-driven agent that can be used to look for research articles about scientific topics. We also show how such a system can be assembled from various simple devices and cloud services. The system we describe is not very sophisticated. In fact it is not much better than Cortana at finding things given English input sentence. However we feel it does illustrate the architecture of a voice-driven agent that can be built by gluing together easy to use cloud services.
Our scenario is a researcher sitting near the device and asking about very specific research topics such as “physical models of immune response” or “programming a topological quantum computer”. We assume the user wants a spoken response if that response is simple, but we also realize that this is impractical if the system is creating a list research journal papers. To address this issue, the system also has a display in a web browser. (We note that the Cortana and Google assistant do the same if the response is a list.)
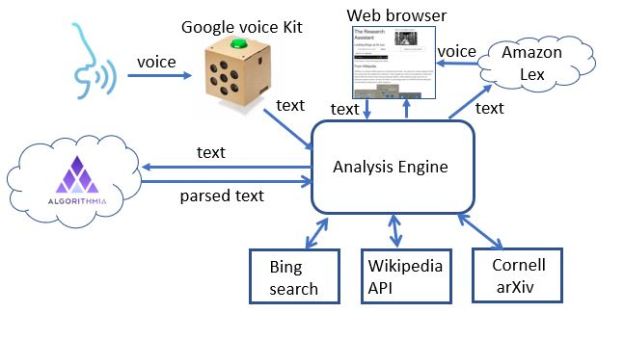
Figure 2 illustrates the basic architecture of the system.
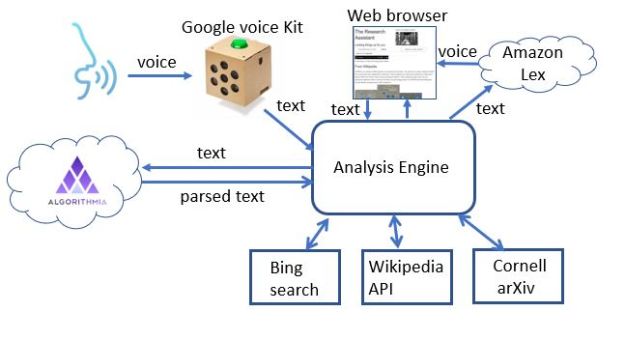
Figure 2. The architecture of the research assistant.
The components of the system are:
- The voice-to-text translator. Here we use a simple voice kit from google. This consists of some special hardware and a raspberry pi 2 computer all packaged in an elegant cardboard box. You wake the system up by pressing the botton on top and speak. The audio is captured and sent to the google voice service for transcription and it is returned as a text string.
- The next step is to parse the text string into the components that will allow us to extract the topics of the query. This is another cloud service call. This time it is to Algorithmia.com and the service is called key phrases. (we wrote about this in a previous article.) The service takes English sentences and invoked Googles ParsyMcParseface (another Algorithmia.com AI service) and returns a list composed of three types of phrases: subject (s), actions (a) and objects (o). It also flags prepositional phrases with a “/” character. So for example, “I am interested in physical models of immune response” returns
[‘s: I ‘, ‘a: am ‘, ‘o: interested /in physical models /of immune response.’]
- The analysis engine is a 500-line Python Dash-based web server that extracts the topics and a few other items of interest and decides how to search and display the results on the browser. There are three web services used for the search: Wikipedia, Bing and Cornell’s ArXiv service[1]. To see how this works, consider the example the sentence “research papers by Michael Eichmair about the gannon-lee singularity are of interest“. The analysis engine detects the topic as the gannon-lee singularity and Michael Eichmar as the author. The fact that research papers are of interest indicates that the we should look in the Cornell ArXiv repository of papers. (The results for this query are at the end of this section). (Truth in advertising: our parser and analysis are far from perfect. For example, “tell me about Deep Learning” vs “tell me about deep learning” yield two different parses. The first yields
[‘a: tell ‘, ‘o: me /about Deep Learning ‘]
which is fine. But the second gives us
[‘a: tell ‘, ‘o: me about deep ‘, ‘a: learning ‘]
which causes the analysis to fail. )
- Finally, we use the Amazon Lex services to generate the audio reading of the Wikipedia results. If you have an aws account, the Python API is easy to use.
Examples
Figure 3 illustrates the interface. We have started with the statement “I am interested in physical models of immune response.”
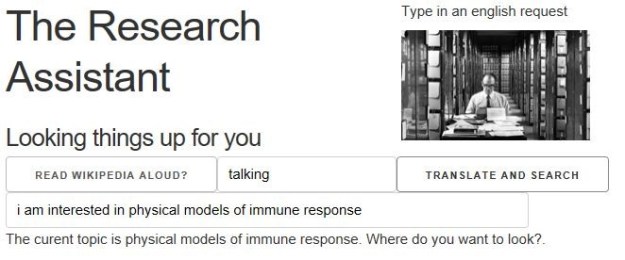
Figure 3. The interface provides a switch to allow the Wikipedia response to read aloud. In this case we have typed the English statement of intent into the query box and hit the “Translate and Search” button.
We respond with the phrase “look for it in Wikipedia” and get the result in figure 4. Following that response, we say “how about research papers” and we get the response in figure 5.
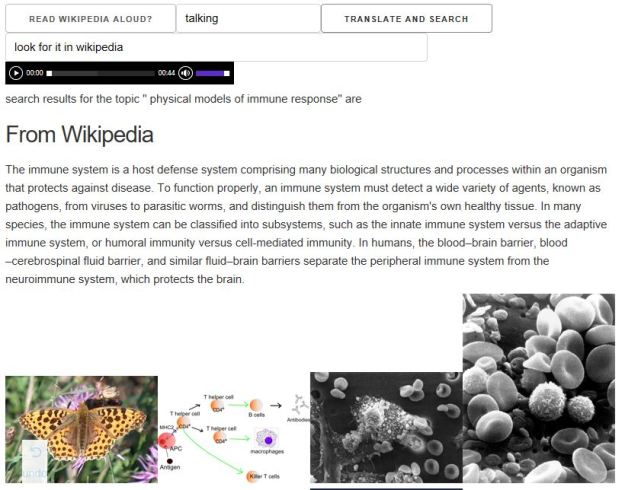
Figure 4. The response to “look for it in wikipedia”. A short summary from Wikipedia is extracted along with related images found on the subject. The spoken response is controlled by the audio control at the top of the response.

Figure5. The mention of research papers suggest that we should consult the Cornell library arXiv. Shown above is only the first result of 10 listed on the page.
Returning to the example mentioned above “research papers by Michael Eichmair about the gannon-lee singularity are of interest” we get the following results. You will notice that the Wikipedia result is a default hit for “big bang singularity” and not directly related to the precise query. The Bing results and the ArXiv hits are accurate.
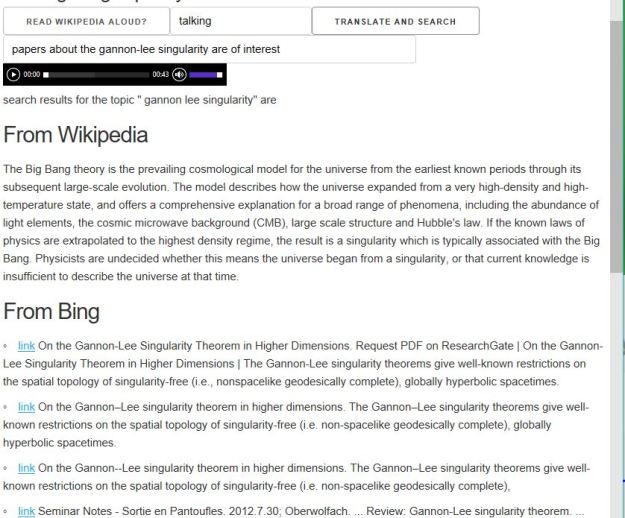
Figure 6. Results for the query “research papers by Michael Eichmair about the gannon-lee singularity are of interest”. (This page was slightly edited to shorten the list of Bing results.)
The system has a limited capability to pull together concepts that are distributed over multiple sentences. For example the input string “what are anyons? How do they relate to topological quantum computation?” will build the topic “anyons topological quantum computation”.
If you are interested in trying to use the system point your browser here. I will try keep it up and running for a few months. There is no voice input because that requires a dedicated Google voice kit on your desk. You need to decide if you want to have a playback of the audio for Wikipedia summaries. If you don’t want it, simply press the “Read Aloud” button. Then enter a query and press the “Translate and Search” button. Here are some samples to try:
- what did they say about laughter in the 19th century?
- are there research papers about laughter by Sucheta Ghosh?
- what can you tell me about Quantum Entanglement research at Stanford? (this one fails!)
- what can you tell me about research on Quantum Entanglement at Stanford?
- what are anyons? How do they relate to topological quantum computation?
- Who was Winslow Homer? (this one give lots of images)
- I am interested in gravitational collapse. (respond with web, Wikipedia or arxiv)
As you experiment, you will find MANY errors. This toy is easily confused. Please email me examples that break it. Of course, feedback and suggestions are always welcome. I can make some of the source code available if there is interest. However, this is still too unreliable for public github.
[1] There are other arguably superior sources we would like to have used. For example, Google Scholar would be perfect, but they have legal restrictions on invoking that service from an application like ours. Dblp is also of interest but it is restricted to computer science.

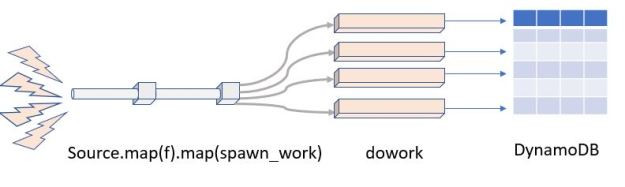
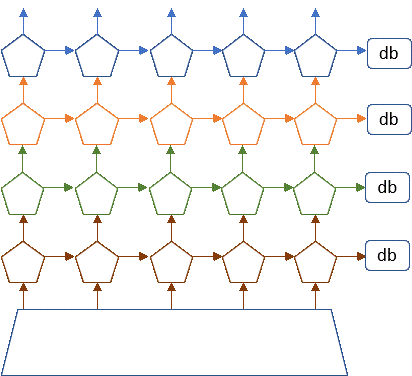 Figure 7. Conceptual view of microservices as stateless services communicating with each other and saving needed state in distribute databases or tables.
Figure 7. Conceptual view of microservices as stateless services communicating with each other and saving needed state in distribute databases or tables.